

When someone searching enters a query into a search engine, such as “top 10 movies of 2020,” the search engine may return results showing links to several webpages relevant to the search query.
It may also show results that link to several webpages that include lists of the top movies of 2020.
A patent granted to Google relates to lists of ranked entities in search results which are based on the documents that returned in response to queries about specific categories of entities.
This may be the top movies of 2020 or the best novels of 2020.
It could be the best science fiction books of 2020 or the best drama TV Series of 2020.
I searched for different types of entities which resulted in carousels showing off ranked entities for my queries:
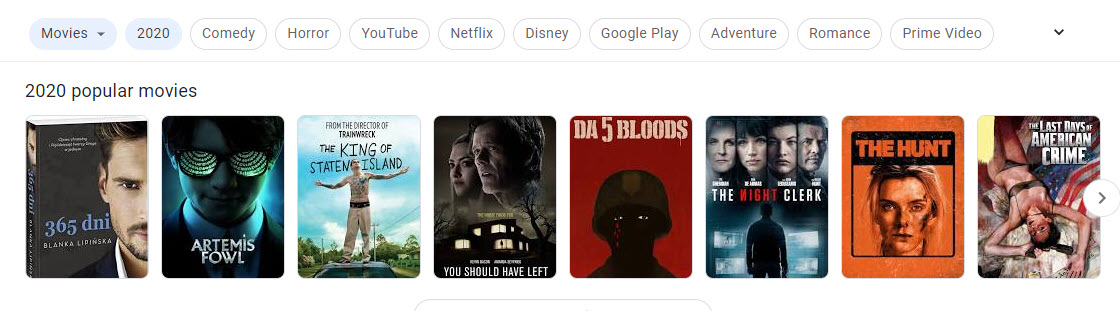
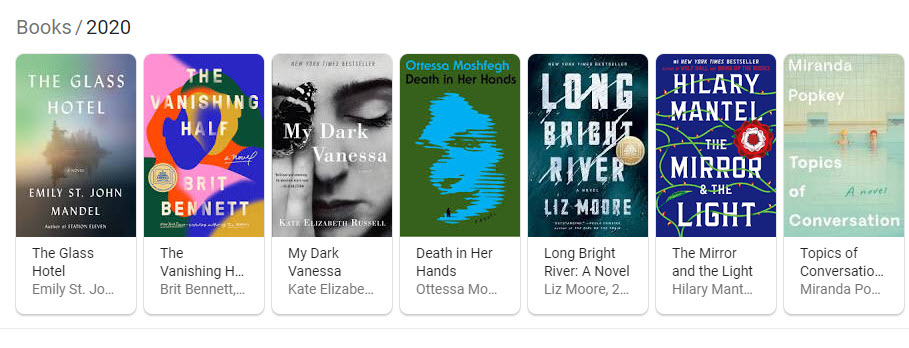
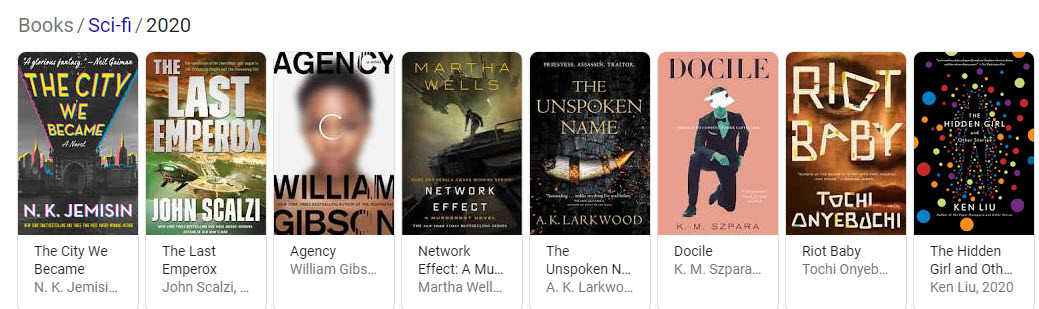
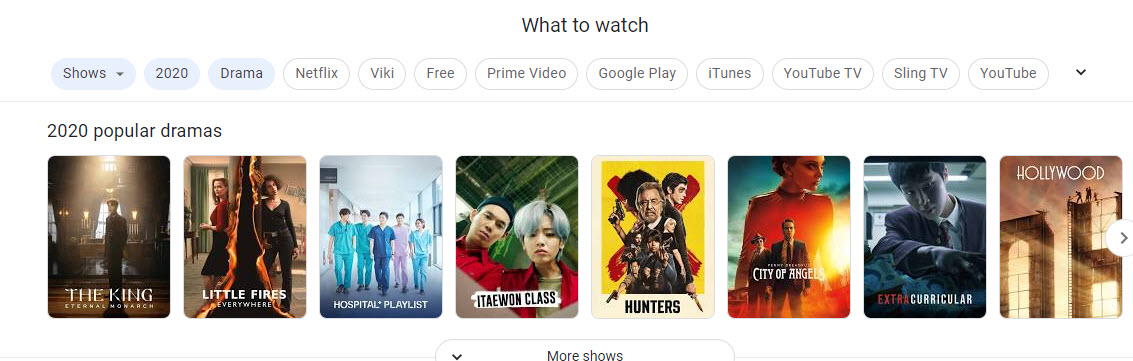
The Process Behind Showing Ranked Lists of Entities
The method from the patent includes:
- Sending a query.
- Receiving information regarding documents relevant to the query.
- Identifying the entities associated with the documents.
- Determining a category for the query based on the query or a topic of documents returned and the entities within those documents.
- Determining that an entity list should be presented in response to the query.
- Presenting SERPs based on determining that the entity list should be presented in response to the query.
How Categories for Entities in Ranked Lists Are Determined
The SERPs may include a list with information identifying the entities.
Determining the category may include generating a score based on:
- Whether the query includes terms associated with the category, where determining the category may be based on the generated score.
- At least some of the documents are associated with a topic associated with the category, where determining the category may be based on the generated score.
- At least some of the entities, associated with the category, where determining the category may be based on the generated score.
- Whether the query includes blacklisted terms, where determining that the entity list should be presented in response to the query may be based on the generated score.
Ranking the Entities in These Lists
The process behind ranking entities may include:
- Where the search result document may include information about the entities in an order based on the ranking
- Generating a score for each of the entities, where the scores are based on the relevance of the particular entity to a particular document.
The process behind this patent involves:
- Receiving a query.
- Receiving information regarding documents relevant to the query.
- Identifying entities associated with the documents.
- Determining a category for the query based on the query, a topic of the documents, and the entities.
- Determining, based on the query and the category, that an entity list should be presented in response to the query.
- Presenting a search result based on determining that the entity list should be presented in response to the query.
The search result document may include a list with information identifying the entities.
The search result document may further include links to the documents that are relevant to the query.
This patent can be found at:
Generating ranked lists of entities
Inventors: Toshiaki Fujiki, Slaven Bilac, Kavi J. Goel, Shuhei Takahashi, Tomohiko Kimura
Assignee: Google LLC
US Patent: 10,691,702
Granted: June 23, 2020
Filed: August 31, 2017
Abstract
“A device may be configured to receive a query; receive information regarding documents that are relevant to the query; identify entities associated with the documents; determine a category for the query based on the query, a topic of the documents, and the entities; determine, based on the query and the category, that an entity list should be presented in response to the query; and present a search result document based on determining that the entity list should be presented in response to the query. The search result document may include a list with information identifying the entities.”
Extracting & Categorizing Entities
The patent provides examples of the extraction and categorization of entities from webpages, and other documents:
- A document may include text, images, etc., regarding entities.
- An entity may be extracted and/or identified from a document by comparing the text, images, etc., to a repository that includes information regarding entities.
- For example, an entity may be associated with the movie “Toy Story 3”.
- Another entity may be associated with the song “Party Rock Anthem”.
- Another entity may be associated with the book “Hitchhiker’s Guide to the Galaxy”.
- Entities may then be categorized. For example, categories of entities may include “movies,” “songs,” or “books”.
The repository mentioned in this patent is likely Google’s Knowledge Graph.
I searched for “Best Planet of the Apes Movies,” and if you hover over one of them, you see more information about each of the movies:
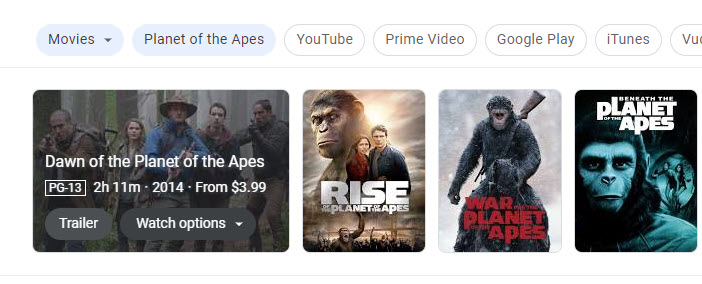
The patent does tell us that they may show additional information about attributes of ranked entities that they are returning:
“For example, user interface 145 may include images and links associated with the entities. Additionally, or alternatively, user interface 145 may also include other information associated with entities, such as attribute information–e.g., release date, music credit, producer credit, production company, or the like. As shown in FIG. 1C, user interface 145 may include, for instance, link 110 and image 115 associated with Toy Story 3, as well as links and images respectively associated with Inception and The Social Network.”
This is so that if you are potentially interested in finding out more about one of the entities shown in a ranked list, that you can find out enough to watch it, or read it, or listen to it.
Entity Extraction for Rankings
The documents that might be returned in response to a query could include documents such as “webpages, news articles, image results, blog documents, or the like.”
The results identification aspect of this process where entities are identified could supply information about the attributes of those entities.
Entities may be ranked based on factors to determine scores for those entities.
One may be if the entity is extracted from a document that has a less relevant topic:
“For example, assume that a first entity associated with the movie Toy Story 3 is extracted from a document with a topic relating to “football,” while a second entity associated with the movie Inception is extracted from a document with a topic relating to “movies.” Entity ranking engine 230 may determine that the first entity has a lower relevance to the result from which the first entity was extracted than the relevance of the second entity to the result from which the second entity was extracted.”
The terms in a document that an entity is extracted from may be reviewed.
An IR (information retrieval) score for the document from which the ranked entity was extracted may be used to determine an entity score used to rank that entity, based on how relevant the page was to the query.
So an entity to be ranked for “best science fiction novels of 2020” from a page that had a high IR score for the query, “best science fiction novels of 2020,” would potentially have a higher entity score than an entity from a page that has a high IR score for “Some OK Science Fiction novels of 2020.”
If a query for ranked entities might include a specific attribute, such as location published, and the query was something such as “Best American Science Fiction novels of 2020”, then ranked entities might be ones that identify the publication location for that entity.
The range of attributes used could be fairly broad, as described in the patent:
“Assume, for example, that the particular entity is associated with a ‘movies’ category. In this example, the attributes may include information, such as release date, lead actor(s) and/or lead actress(es), supporting actor(s) and/or actress(es), box office gross, executive producer credit, music credit, synopsis and/or summary associated with the movie, etc. In other examples, entities associated with different categories may be associated with a different set of attributes. Further assume that the particular entity is associated with Toy Story 3, a movie released in 2010 and that the query includes the term ‘2010.’ Thus, entity ranking engine 230 may identify that the query is associated with a release date attribute associated with the particular entity.”
Another factor may be if the query contains blacklisted terms.
These could be adult terms or offensive terms.
Another factor could be if the query is associated with entity lists. Entity lists include phrases such as:
- “top”
- “of 2020”
- “Best”
- “Best of”
If the query contains such a term, entities from pages that may also be relevant for those may score higher in a list of ranked entities.
When a query includes a trigger that calls for an entity list, it may show a carousel or a list of entities.
If it does not contain such a trigger, it may not show a list of entities.
Ranked Entities Results
This patent describes a process that you can easily get caught up in once you learn about it.
I found myself going through queries such as “Best Comedies 1975” and for years following that one.
And “Best TV Shows 1980” and for years after that.
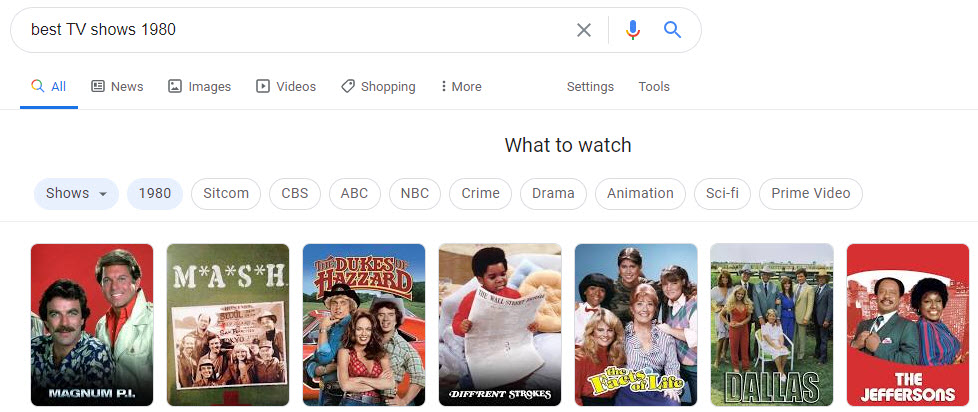


If you do those searches, you will see that the documents those entities come from in the rest of the SERPs for them are ones about “Top” or “Best” results, and the queries for them triggered query lists showing those carousels.
There are other ranked entities lists you can find as well, like Pulitzer award winners:

Or Best Houseplants for air quality:
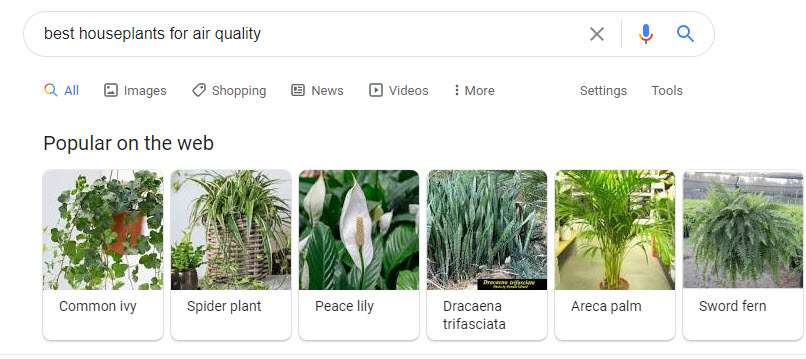
Exploring these Carousels for ranked entities was almost as much fun as looking at the Semantic Ontology-based categories in image Search at Google, which I looked at in Google Image Search Labels Becoming More Semantic?
More Resources:
- What Are Entities & Why They Matter for SEO
- Google Search 101: How the Knowledge Graph Works
- New Patent Explains How Google Chooses Images for Knowledge Panels
Image Credits
All screenshots taken by author, June 2020
