

Can’t wait for your new content to get indexed?
Learn why it’s so hard to estimate how long indexing may take and what you can do to speed things up.
Indexing is the process of downloading information from your website, categorizing it, and storing it in a database. This database – the Google index – is the source of all information you can find via Google Search.
Pages that aren’t included in the index cannot appear in search results, no matter how well they match a given query.
Let’s assume you’ve recently added a new page to your blog. In your new post, you discuss a trending topic, hoping it will provide you with a lot of new traffic.
But before you can see how the page is doing on Google Search, you have to wait for it to be indexed.
So, how long exactly does this process take? And when should you start worrying that the lack of indexing may signal technical problems on your site?
Let’s investigate!
How Long Does Indexing Take? Experts’ Best Guesses
The Google index contains hundreds of billions of web pages and takes up over 100 million gigabytes of memory.
Additionally, Google doesn’t limit how many pages on a website can be indexed. While some pages may have priority in the indexing queue, pages generally don’t have to compete for indexing.
There should still be room for one more small page in this colossal database, right? There’s no need to worry about your blog entry? Unfortunately, you might have to.
Google admits that not every page processed by its crawlers will be indexed.
In January 2021, Google Search Advocate, John Mueller, elaborated on the topic, disclosing that it’s pretty normal that Google does not index all the pages of a large website.
He explained that the challenge for Google is trying to balance wanting to index as much content as possible with estimating if it will be useful for search engine users.
Therefore, in many cases, not indexing a given piece of content is Google’s strategic choice.
Google doesn’t want its index to include pages of low quality, duplicate content, or pages unlikely to be looked for by users. The best way to keep spam out of search results is not to index it.
But as long as you keep your blog posts valuable and useful, they’re still getting indexed, right?
The answer is complicated.
Tomek Rudzki, an indexing expert at Onely – a company I work for – calculated that, on average, 16% of valuable and indexable pages on popular websites never get indexed.
Is There A Guarantee That Your Page Will Be Indexed?
As you may have already guessed from the title of this article, there is no definitive answer to this indexing question.
You won’t be able to set yourself a calendar reminder on the day your blog post is due to be indexed.
But many people have asked the same question before, urging Googlers and experienced SEO pros to provide some hints.
John Mueller says it can take anywhere from several hours to several weeks for a page to be indexed. He suspects that most good content is picked up and indexed within about a week.
Research conducted by Rudzki showed that, on average, 83% of pages are indexed within the first week of publication.
Some pages have to wait up to eight weeks to get indexed. Of course, this only applies to pages that do get indexed eventually.
Crawl Demand And Crawl Budget
For a new page on your blog to be discovered and indexed, Googlebot has to recrawl the blog.
How often Googlebot recrawls your website certainly impacts how quickly your new page will get indexed, and that depends on the nature of the content and the frequency with which it gets updated.
News websites that publish new content extremely often need to be recrawled frequently. We can say they’re sites with high crawl demand.
An example of a low crawl demand site would be a site about the history of blacksmithing, as its content is unlikely to be updated very frequently.
Google automatically determines whether the site has a low or high crawl demand. During initial crawling, it checks what the website is about and when it was last updated.
The decision to crawl the site more or less often has nothing to do with the quality of the content – the decisive factor is the estimated frequency of updates.
The second important factor is the crawl rate. It’s the number of requests Googlebot can make without overwhelming your server.
If you host your blog on a low-bandwidth server and Googlebot notices that the server is slowing down, it’ll adjust and reduce the crawl rate.
On the other hand, if the site responds quickly, the limit goes up, and Googlebot can crawl more URLs.
What Needs To Happen Before Your Page Is Indexed?
Since indexing takes time, one can also wonder – how exactly is that time spent?
How is the information from your website categorized and included in the Google index?
Let’s discuss the events that must happen before the indexing.
Content Discovery
Let’s go back to the example in which you posted a new blog entry. Googlebot needs to discover this page’s URL in the first step of the indexing pipeline.
It can happen by:
- Following internal links you provided on other pages of your blog.
- Following external links created by people who found your new content useful.
- Going through an XML sitemap that you uploaded to Google Search Console.
The fact that the page has been discovered means that Google knows about its existence and URL.
Crawling
Crawling is the process of visiting the URL and fetching the page’s contents.
While crawling, Googlebot collects information about a given page’s main topic, what files this page contains, what keywords appear on it, etc.
After finding links on a page, the crawler follows them to the next page, and the cycle continues.
It’s important to remember that Googlebot follows the rules set up by robots.txt so that it won’t crawl pages blocked by the directives you provide in that file.
Rendering
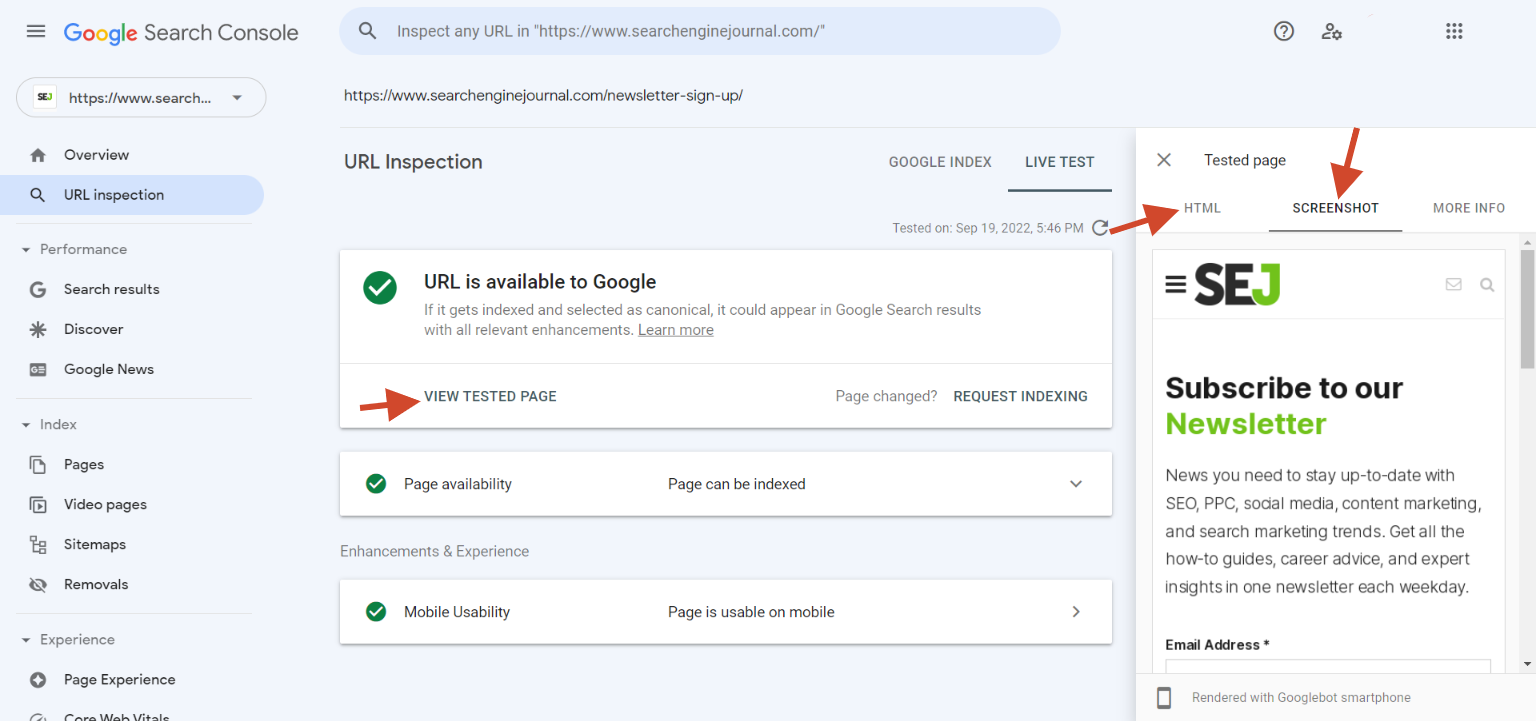 Screenshot from Google Search Console, September 2022
Screenshot from Google Search Console, September 2022The rendering needs to happen for Googlebot to understand both the JavaScript content and images, audio, and video files.
These types of files always were a bigger struggle for Google than HTML.
Google’s developer advocate, Martin Splitt, compared rendering to cooking a dish.
In this metaphor, the initial HTML file of a website with links to other contents is a recipe. You can press F12 on your keyboard to view it in your browser.
All the website’s resources, such as CSS, JavaScript files, images, and videos, are the ingredients necessary to give the website its final look.
When the website achieves this state, you’re dealing with the rendered HTML, more often called Document Object Model.
Martin also said that executing JavaScript is the very first rendering stage because JavaScript works like a recipe within a recipe.
In the not-too-distant past, Googlebot used to index the initial HTML version of a page and leave JavaScript rendering for late due to the cost and time-consuming nature of the process.
The SEO industry referred to that phenomenon as “the two waves of indexing.”
However, now it seems that the two waves are no longer necessary.
Mueller and Splitt admitted that, nowadays, nearly every new website goes through the rendering stage by default.
One of Google’s goals is getting crawling, rendering, and indexing to happen closer together.
Can You Get Your Page Indexed Faster?
You can’t force Google to index your new page.
How quickly this happens is also beyond your control. However, you can optimize your pages so that discovering and crawling run as smoothly as possible.
Here’s what you need to do:
Make Sure Your Page Is Indexable
There are two important rules to follow to keep your pages indexable:
- You should avoid blocking them by robots.txt or the noindex directive.
- You should mark the canonical version of a given content piece with a canonical tag.
Robots.txt is a file containing instructions for robots visiting your site.
You can use it to specify which crawlers are not allowed to visit certain pages or folders. All you have to do is use the disallow directive.
For example, if you don’t want robots to visit pages and files in the folder titled “example,” your robots.txt file should contain the following directives:
User-agent: * Disallow: /example/
Sometimes, it’s possible to block Googlebot from indexing valuable pages by mistake.
If you are concerned that your page is not indexed due to technical problems, you should definitely take a look at your robots.txt.
Googlebot is polite and won’t pass any page it was told not to to the indexing pipeline. A way to express such a command is to put a noindex directive in:
- X-Robots-tag in the HTTP header response of your page’s URL.
- Meta robots tag in the <head> section of your page.
Make sure that this directive doesn’t appear on pages that should be indexed.
As we discussed, Google wants to avoid indexing duplicate content. If it finds two pages that look like copies of each other, it will likely only index one of them.
The canonical tag was created to avoid misunderstandings and immediately direct Googlebot to the URL that the website owner considers the original version of the page.
Remember that the source code of a page you want to be present in the Google index shouldn’t point to another page as canonical.
Submit A Sitemap
A sitemap lists your website’s every URL that you would like to get indexed (up to 50,000).
You can submit it to Google Search Console to help Google discover the sitemap more quickly.
With a sitemap, you make it easier for Googlebot to discover your pages and increase the chance it’ll crawl those it didn’t find while following internal links.
It’s a good practice to reference the sitemap in your robots.txt file.
Ask Google To Recrawl Your Pages
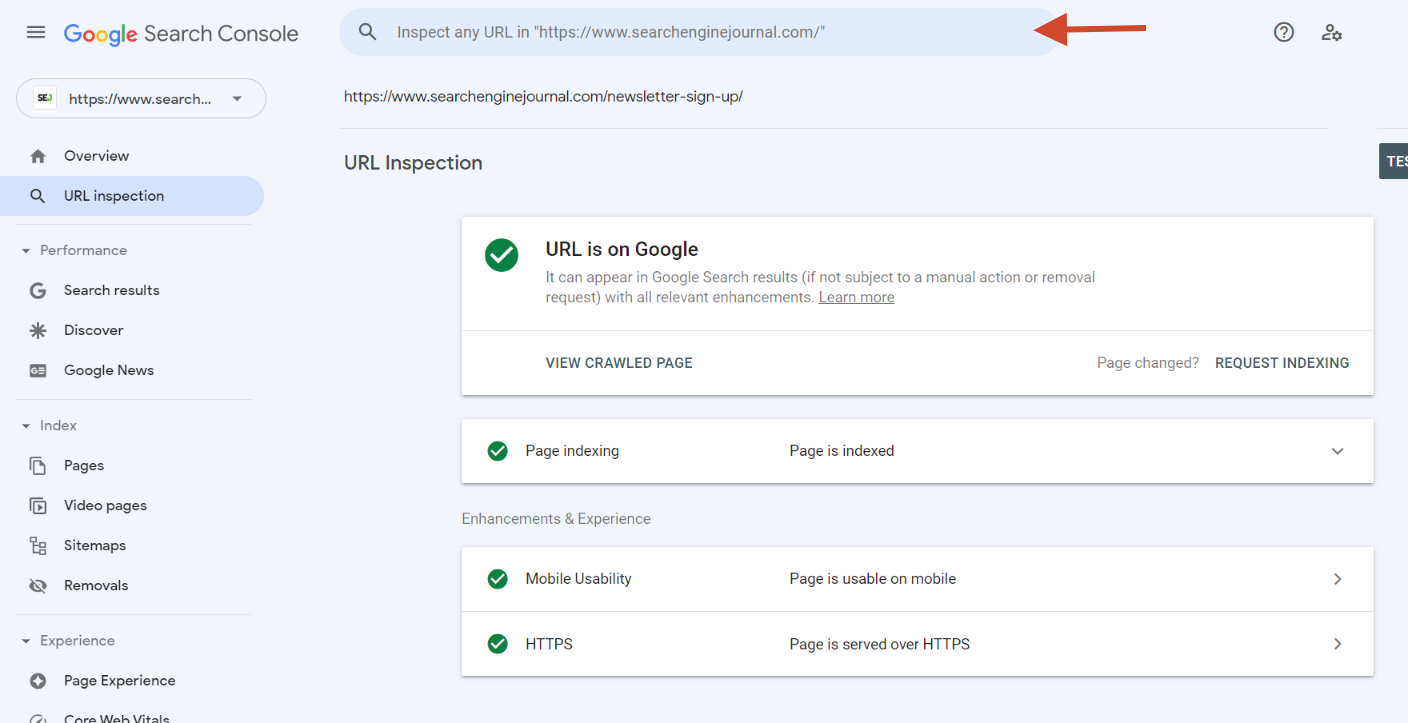 Screenshot from Google Search Console, September 2022
Screenshot from Google Search Console, September 2022You can request a crawl of individual URLs using the URL Inspection tool available in Google Search Console.
It still won’t guarantee indexing, and you’ll need some patience, but it’s another way to make sure Google knows your page exists.
If Relevant, Use Google’s Indexing API
Indexing API is a tool allowing you to notify Google about freshly added pages.
Thanks to this tool, Google can schedule the indexing of time-sensitive content more efficiently.
Unfortunately, you can’t use it for your blog posts because, currently, this tool is intended only for pages with job offers and live videos.
While some SEO pros use the Indexing API for other types of pages – and it might work short-term – it’s doubtful to remain a viable solution in the long run.
Prevent The Server Overload On Your Site
Finally, remember to ensure good bandwidth of your server so that Googlebot doesn’t reduce the crawl rate for your website.
Avoid using shared hosting providers, and remember to regularly stress-test your server to make sure it can handle the job.
Summary
It’s impossible to precisely predict how long it will take for your page to be indexed (or whether it will ever happen) because Google doesn’t index all the content it processes.
Typically indexing occurs hours to weeks after publication.
The biggest bottleneck for getting indexed is getting promptly crawled.
If your content meets the quality thresholds and there are no technical obstacles for indexing, you should primarily look at how Googlebot crawls your site to get fresh content indexed quickly.
Before a page is redirected to the indexing pipeline, Googlebot crawls it and, in many cases, renders embed images, videos, and JavaScript elements.
Websites that change more often and, therefore, have a higher crawl demand are recrawled more often.
When Googlebot visits your website, it will match the crawl rate based on the number of queries it can send to your server without overloading it.
Therefore, it’s worth taking care of good server bandwidth.
Don’t block Googlebot in robots.txt because then it won’t crawl your pages.
Remember that Google also respects the noindex robots meta tag and generally indexes only the canonical version of the URL.
More resources:
- What To Do When Google Is Ranking The Wrong Page For Your Keywords
- Best Browser Add-Ons For Analyzing Page Speed
- Advanced Technical SEO: A Complete Guide
Featured Image: Kristo-Gothard Hunor/Shutterstock
