
I came across a very interesting online tool while I did some research for the post about proper title capitalization. The tool is about the use of the English language in real life and called WordCount™.
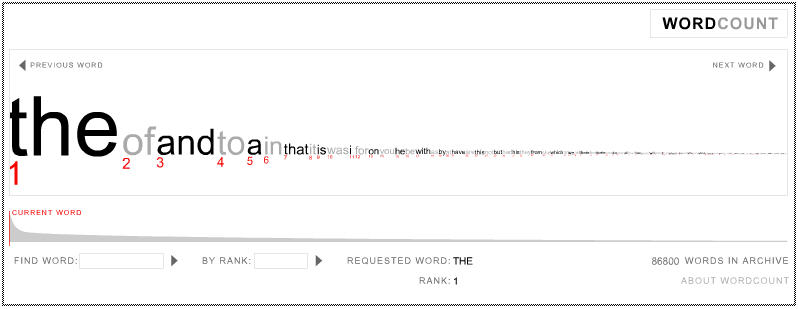
WordCount™ is an artistic experiment in the way we use language. It presents the 86,800 most frequently used English words, ranked in order of commonness. Each word is scaled to reflect its frequency relative to the words that precede and follow it, giving a visual barometer of relevance. The larger the word, the more we use it. The smaller the word, the more uncommon it is.
WordCount™ data currently comes from the British National Corpus®, a 100 million words collection of samples of written and spoken language from a wide range of sources, designed to represent an accurate cross-section of current English usage. WordCount includes all words that occur at least twice in the BNC®. In the future, WordCount™ will be modified to track word usage within any desired text, website, and eventually the entire Internet.
Here is a nice shot of how the results look like.
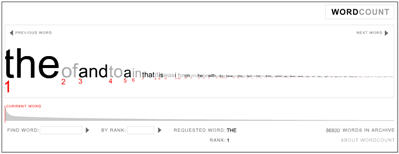
To the look and purpose of the tool did the create state the following.
WordCount™ was designed with a minimalist aesthetic, to let the information speak for itself. The interface is clean, basic and intuitive. The goal is for the user to feel embedded in the language, sifting through words like an archaeologist through sand, awaiting the unexpected find. Observing closely ranked words tells us a great deal about our culture. For instance, “God” is one word from “began”, two words from “start”, and six words from “war”. Another sequence is “america ensure oil opportunity”. Conspiracists unite! As ever, the more one explores, the more is revealed.
WordCount Conspiracy.
The author published a number of WordCount sequences that were discovered by people in the fast amount of data rankings and emailed to him. The results are quite funny and show that some people have certainly too much free time on their hand. Look for yourself. Conspiracists unite!
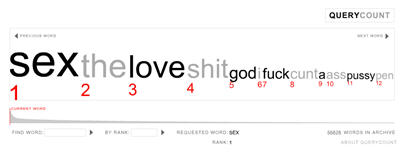
I like even more the spin off tool of WordCount titled QueryCount.
QueryCount shows the top words queried for at WordCount by users of the site. It is something like a mini-Google Zeitgeist, only a lot smaller, but certainly not censored like its big brother from Google 🙂
The results shown by QueryCount seem to be about right and more or less represent what I would expect as the top words used in queries on the major search engines as well.
I was checking out the results for 2006 at Google Zeitgeist and my little modified picture below expresses what my thoughts were when I looked at them.
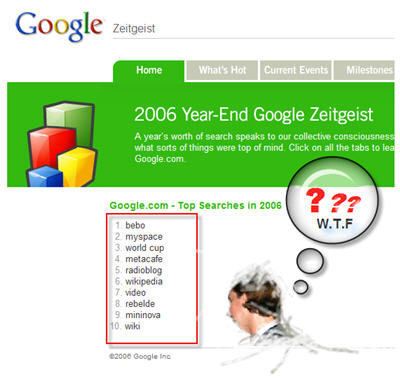
The number one term “bebo” did really have many searches. Bebo is like another MySpace, Xanga or Yahoo! 360. Michael Birch and his wife founded bebo.com in 2005. It saw a huge increase in popularity and number of memberships last year. The site did break into the Alexa Top 100 already.
I have not checked it out myself yet, but I am intrigued.
The Soccer World Cup in Germany was big of course. Metacafe.com is another social network for video sharing. Radioblog is the music search engine “radio.blog.club” at radioblogclub.com. Radio.blog is the web music player powered by Adobe Flash and PHP used by the site.
I took the number two word “myspace” and the number six word “Wikipedia” of the top 10 list and hopped over to Google Trends to compare the search trends of the two words with the trends of the top two words of QueryCount.
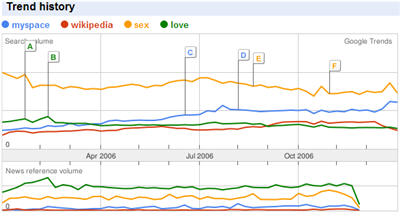
The number one QueryCount word clearly beats the number two word of Google Zeitgeist.
It should have been the number Two in Google Zeitgeist instead. The number One actually, because “bebo” did also not have as much searches to beat the real #1.
I can to some degree understand why Google censors words like p**n in something like Google Zeitgeist, but the word Sex? C’mon. Show the world that Americans are not as prude as people say about them. There is nothing wrong with sex. Nobody would be around to talk about it without it.
It is interesting to see how uncensored tools like QueryCount show the real human US. We are what we are and there is no reason to be ashamed to be human. Make love and peace…
Cheers!
Carsten Cumbrowski
Owner of the uncensored Internet Marketing Resources Portal at Cumbrowski.com

{kind=link}