



Is it just me, or does the words “meta robots tags” and “robots.txt” sound like something Schwarzenegger said in “Terminator 2”?
That’s one reason why I started working in SEO — it seemed futuristic but overwhelmingly techy for my skills at the time.
Hopefully, this article makes setting up your meta robots tags and robots.txt files less nauseating. Let’s get started.
Meta Robots Tags vs. Robots.txt
Before we dig into the basics of what meta robots tags and robots.txt files are, it’s important to know that there is not one side that’s better than the other to use in SEO.
Robots.txt files instruct crawlers about the entire site.
While meta robots tags get into the nitty-gritty of a specific page.
I prefer to use meta robots tags for many things that other SEO professionals may just use the simplicity of the robots.txt file.
There is no right or wrong answer. It’s a personal preference based on your experience.
What Is Robots.txt?
A robots.txt file tells crawlers what should be crawled.
It’s part of the robots exclusion protocol (REP).
Googlebot is an example of a crawler.
Google deploys Googlebot to crawl websites and record information on that site to understand how to rank the site in Google’s search results.
You can find any site’s robots.txt file by add /robots.txt after the web address like this:
www.mywebsite.com/robots.txt
Here is what a basic, fresh, robots.txt file looks like:
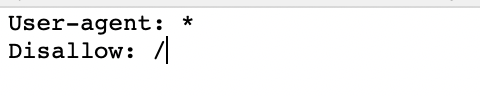
The asterisk * after user-agent tells the crawlers that the robots.txt file is for all bots that come to the site.
The slash / after “Disallow” tells the robot to not go to any pages on the site.
Here is an example of Moz’s robots.txt file.

You can see they are telling the crawlers what pages to crawl using user-agents and directives. I’ll dive into those a little later.
Why Is Robots.txt Important?
I can’t tell how many clients come to me after a website migration or launching a new website and ask me: Why isn’t my site ranking after months of work?
I’d say 60% of the reason is that the robots.txt file wasn’t updated correctly.
Meaning, your robots.txt file still looks like this:
This will block all web crawlers are visiting your site.
Another reason robots.txt is important is that Google has this thing called a crawl budget.
Google states:
“Googlebot is designed to be a good citizen of the web. Crawling is its main priority, while making sure it doesn’t degrade the experience of users visiting the site. We call this the “crawl rate limit,” which limits the maximum fetching rate for a given site.
Simply put, this represents the number of simultaneous parallel connections Googlebot may use to crawl the site, as well as the time it has to wait between the fetches.”
So, if you have a big site with low-quality pages that you don’t want Google to crawl, you can tell Google to “Disallow” them in your robots.txt file.
This would free up your crawl budget to only crawl the high-quality pages you want Google to rank you for.
There are no hard and fast rules for robots.txt files…yet.
Google announced a proposal in July 2019 to begin implementing certain standards, but for now, I’m following the best practices I’ve done for the past few years.
Robots.txt Basics
How to Use Robots.txt
Using robots.txt is vital for SEO success.
But, not understanding how it works can leave you scratching your head as to why you aren’t ranking.
Search engines will crawl and index your site based on what you tell them to in the robots.txt file using directives and expressions.
Below are common robots.txt directives you should know:
User-agent: * — This is the first line in your robots.txt file to explain to crawlers the rules of what you want them to crawl on your site. The asterisk informs all spiders.
User-agent: Googlebot — This tells only what you want Google’s spider to crawl.
Disallow: / — This tells all crawlers to not crawl your entire site.
Disallow: — This tells all crawlers to crawl your entire site.
Disallow: /staging/ — This tells all crawlers to ignore your staging site.
Disallow: /ebooks/* .pdf — This tells crawlers to ignore all your PDF formats which may cause duplicate content issues.
User-agent: Googlebot
Disallow: /images/ — This tells only the Googlebot crawler to ignore all images on your site.
* — This is seen as a wildcard that represents any sequence of characters.
$ — This is used to match the end of the URL.
To create a robots.txt file, I use Yoast for WordPress. It already integrates with other SEO features on my sites.
But, before you start to create your robots.txt file, here are a few basics to remember:
- Format your robots.txt correctly. SEMrush does a great example of how a robots.txt should be properly formatted. You see the structure follows this pattern: User-agent → Disallow → Allow → Host → Sitemap. This lets search engine spiders access categories and web pages in the right order.

- Make sure that every URL you want to “Allow:” or “Disallow:” is placed on a separate line as Best Buy does below. And, do not separate with spacing.
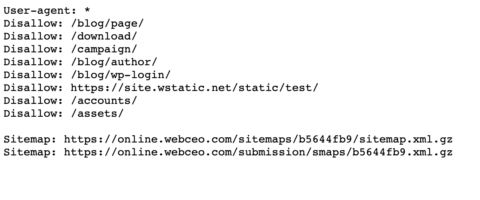
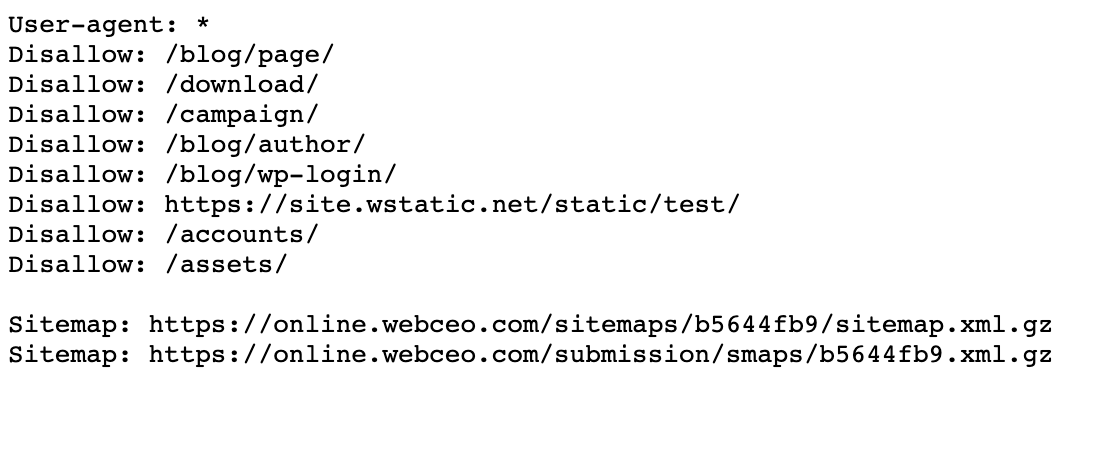
- Always use lowercase to name your robots.txt like WebCEO does.
- Do not use any special characters except * and $. Other characters are not recognized.
- Create separate robots.txt files for different subdomains. For example, “hubspot.com” and “blog.hubspot.com” have individual files and both have different robots.txt files.
- Use # to leave comments in your robots.txt file. Crawlers do not honor lines with the # character like I did here with this robots.txt file.
- If a page is disallowed in the robots.txt files, the link equity will not pass.
- Never use the robots.txt to protect or block sensitive data.
What to Hide with Robots.txt
Robots.txt files are often used to exclude specific directories, categories, or pages from the SERPs.
You can exclude by using the “disallow” directive.
Here are a few common pages I hide using a robots.txt file:
- Pages with duplicate content (often printer-friendly content)
- Pagination pages
- Dynamic product and service pages
- Account pages
- Admin pages
- Shopping cart
- Chats
- Thank you pages
This is super helpful for ecommerce sites using parameters like Macy’s does.

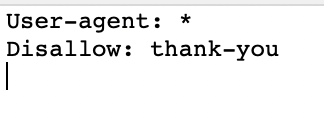
And, you can see here how I disallowed a thank page.

It’s important to know that not all crawlers will follow your robots.txt file.
Bad bots can completely ignore your robots.txt file, so make sure you’re not keeping sensitive data on blocked pages.
Common Robots.txt Mistakes
After managing robots.txt files for 10+ years now, here are a few of the common mistakes I see:
Mistake #1: The File Name Contains Upper Case
The only possible file name is robots.txt, nor Robots.txt or ROBOTS.TXT.
Stick to lowercase, always when it comes to SEO.
Mistake #2: Not Placing the Robots.Txt File in the Main Directory
If you want your robots.txt file to be found, you have to place it in the main directory of your site.
Wrong
www.mysite.com/tshirts/robots.txt
Correct
www.mysite.com/robots.txt
Mistake #3: Incorrectly Formatted User-Agent
Wrong
Disallow: Googlebot
Correct
User-agent: Googlebot
Disallow: /
Mistake #4: Mentioning Multiple Catalogs in One ‘Disallow’ Line
Wrong
Disallow: /css/ /cgi-bin/ /images/
Correct
Disallow: /css/
Disallow: /cgi-bin/
Disallow: /images/
Mistake #5: Empty Line in ‘User-Agent’
Wrong
User-agent:
Disallow:
Correct
User-agent: *
Disallow:
Mistake #6: Mirror Websites & Url in the Host Directive
Be careful when mentioning ‘host’ directives, so that search engines understand you correctly:
Wrong
User-agent: Googlebot
Disallow: /cgi-bin
Correct
User-agent: Googlebot
Disallow: /cgi-bin
Host: www.site.com
If your site has https, the correct option is:
User-agent: Googlebot
Disallow: /cgi-bin
Host: https://www.site.com
Mistake #7: Listing All the Files Within the Directory
Wrong
User-agent: *
Disallow: /pajamas/flannel.html
Disallow: /pajamas/corduroy.html
Disallow: /pajamas/cashmere.html
Correct
User-agent: *
Disallow: /pajamas/
Disallow: /shirts/
Mistake #8: No Disallow Instructions
The disallow instructions are required so that search engine bots understand your intent.
Wrong
User-agent: Googlebot
Host: www.mysite.com
Correct
User-agent: Googlebot
Disallow:
Host: www.mysite.com
Mistake #9: Blocking Your Entire Site
Wrong
User-agent: Googlebot
Disallow: /
Correct
User-agent: Googlebot
Disallow:
Mistake #10: Using Different Directives in the * Section
Wrong
User-agent: *
Disallow: /css/
Host: www.example.com
Correct
User-agent: *
Disallow: /css/
Mistake #11: Wrong HTTP Header
Wrong
Content-Type: text/html
Correct
Content-Type: text/plain
Mistake #12: No Sitemap
Always place your sitemaps at the bottom of your robots.txt file.
Wrong

Correct

Mistake #13: Using Noindex
Google announced in 2019 that it would no longer acknowledge the noindex directive used in robots.txt files.
So, use the meta robots tags I talk about below instead.
Wrong

Correct
Mistake #14: Disallowing a Page in the Robots.Txt File, but Still Linking to It
If you disallow a page in the robots.txt file, Google will still crawl the page if you have internal links pointing to it.
You need to remove those links for spiders to stop crawling that page completely.
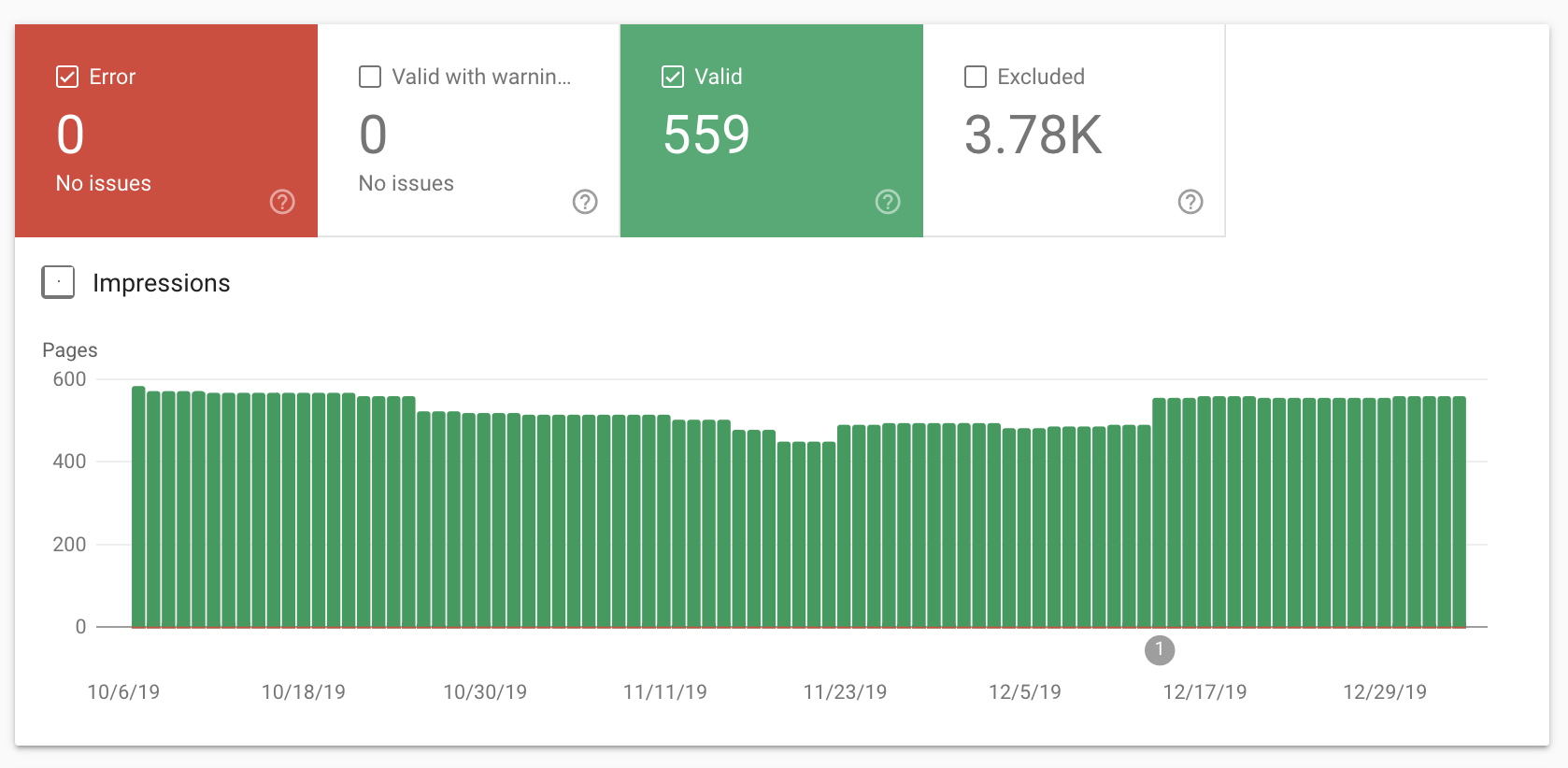
If you’re ever unsure, you can check which pages are being indexed in your Google Search Console Coverage report.
You should see something like this:
And, you can use Google’s robots.txt testing tool.
However, if you’re using the mobile-friendly test tool by Google, it does not follow your rules in the robots.txt file.
What Are Meta Robots Tags?
Meta robots tags (also called meta robots directives) are HTML code snippets that tell search engine crawlers how to crawl and index pages on your website.
The meta robots tags are added to the <head> section of a web page.
Here is an example:
<meta name=”robots” content=”noindex” />
Ther meta robots tags are made up of two parts.
The first part of the tag is name=’’’.
This is where you identify the user-agent. For example, “Googlebot.”
The second part of the tag is content=’’. This where you tell the bots what you want them to do.
Types of Meta Robots Tags
Meta robots tags have two types of tags:
- Meta robots tag.
- X-robots-tag.
Type 1: Meta Robots Tag
Meta robots tags are commonly used by SEO marketers.
It allows you to tell user-agents (think Googlebot) to crawl specific areas.
Here is an example:
<meta name=”googlebot” content=”noindex,nofollow”>
This meta robots tag tells Google’s crawler, Googlebot, to not index the page in the search engines and to not follow any backlinks.
So, this page would not be part of the SERPs.
I would use this meta robots tag for a thank you page.
Here is an example of a thank you page after you download an ebook.
Now, if you look at the backend code, you’ll see it says noindex and nofollow.
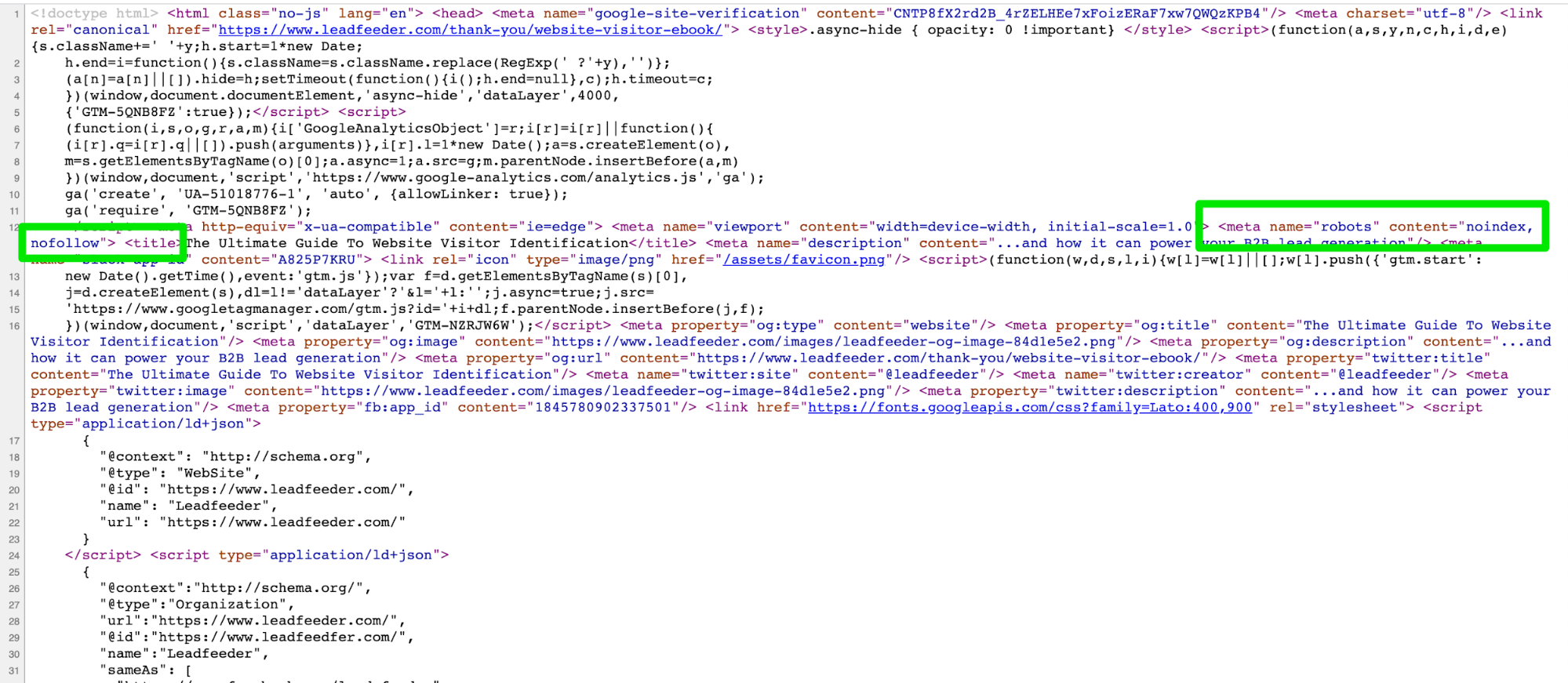
If you’re using different meta robots tag directives for different search user-agents, you’ll need to use separate tags for each bot.
It’s crucial that you do not place the meta robots tags outside of the <head> section. Glenn Gabe shows you why in this case study.
Type 2: X-robots-tag
The x-robots-tag allows you to do the same thing as the meta robots tags but within the headers of an HTTP response.
Essentially, it gives you more functionality than the meta robots tags.
However, you will need access to the .php, .htaccess, or server files.
For example, if you want to block an image or video, but not the entire page, you would use x-robots-tag instead.
Meta Robots Tag Parameters
There are many ways to use meta robots tag directives in the code. But, first, you need to understand what these directives are and what they do.
Here is a break down of meta robots tag directives:
- all – No limitations for indexing and content. This directive is being used by default. It has no impact on the search engines’ work. I’ve used it as a short cut for index, follow.
- index – Allow search engines to index this page in their search results. This is a default. You do not need to add this to your pages.
- noindex – Removes the page from the search engines index and search results. This means searchers will not find your site or click through.
- follow – Allows search engines to follow the internal and external backlinks on that page.
- nofollow – Do not allow following the internal and external backlinks. This means these links will not pass link equity.
- none – The same as noindex, and nofollow meta tags.
- noarchive – Do not show the ‘Saved Copy’ link in the SERPs.
- nosnippet – Do not show the extended description version of this page in the SERPs.
- notranslate – Do not offer this page’s translation in the SERPs.
- noimageindex – Do not index the on-page images.
- unavailable_after: [RFC-850 date/time] – Do not show this page in the SERPs after specified date/time. Use RFC 850 format.
- max-snippet – Establishes a maximum number for the character count in the meta description.
- max-video-preview – Establishes the number of seconds a video will preview.
- max-image-preview – Establishes a maximum size for the image preview.
Sometimes, different search engines accept different meta-tag parameters. Here is a breakdown:
| Value | Bing | Yandex | |
| index | Yes | Yes | Yes |
| noindex | Yes | Yes | Yes |
| none | Yes | Doubt | Yes |
| noimageindex | Yes | No | No |
| follow | Yes | Doubt | Yes |
| nofollow | Yes | Yes | Yes |
| noarchive | Yes | Yes | Yes |
| nosnippet | Yes | No | No |
| notranslate | Yes | No | No |
| unavailable_after | Yes | No | No |
How to Use Meta Robots Tags
If you’re using a WordPress website, there are many plugin options for you to tailor your meta robots tags.
I prefer to use Yoast. It’s an all-in-one SEO plugin for WordPress that provides a lot of features.
But, there’s also Meta Tags Manager plugin and GA Meta Tags plugin.
Joomla users, I recommend EFSEO and Tag Meta.
No matter what your site is built on, here are three tips to using meta robots tags:
- Keep it case sensitive. Search engines recognize attributes, values, and parameters in both uppercase and lowercase. I recommend that you stick to lowercase to improve code readability. Plus, if you’re an SEO marketer, it’s best to get in the habit of using lowercase.
- Avoid multiple <meta> tags. Using multiple meta tags will cause conflicts in code. Use multiple values in your <meta> tag, like this: <meta name=“robots” content=“noindex, nofollow”>.
- Do not use conflicting meta tags to avoid indexing mistakes. For example, if you have multiple code lines with meta tags like this <meta name=“robots” content=“follow”> and this <meta name=“robots” content=“nofollow”>, only “nofollow” will be taken into consideration. This is because robots put restrictive values first.
Robots.txt & Meta Robots Tags Work Together
One of the biggest mistakes I see when working on my client’s websites is when the robots.txt file doesn’t match what you’ve stated in the meta robots tags.
For example, the robots.txt file hides the page from indexing, but the meta robots tags do the opposite.
Remember the example from Leadfeeder I showed above?
So, you’ll notice that this thank you page is disallowed in the robots.txt file and using the meta robots tags of noindex, nofollow.
In my experience, Google has given priority to what is prohibited by the robots.txt file.
But, you can eliminate non-compliance between meta robots tags and robots.txt by clearly telling search engines which pages should be indexed, and which should not.
Final Thoughts
If you’re still reminiscing about the days of buying a Blockbuster movie in a strip mall, then the idea of using robots.txt or meta tags may still seem overwhelming.
But, if you’ve already binge-watched “Stranger Things”, welcome to the future.
Hopefully, this guide provided more insight into the basics of robots.txt and meta tags. If you were hoping for robots flying in on jet packs and time travel after reading this post, I’m sorry.
Image Credits
Featured Image: Paulo Bobita
