

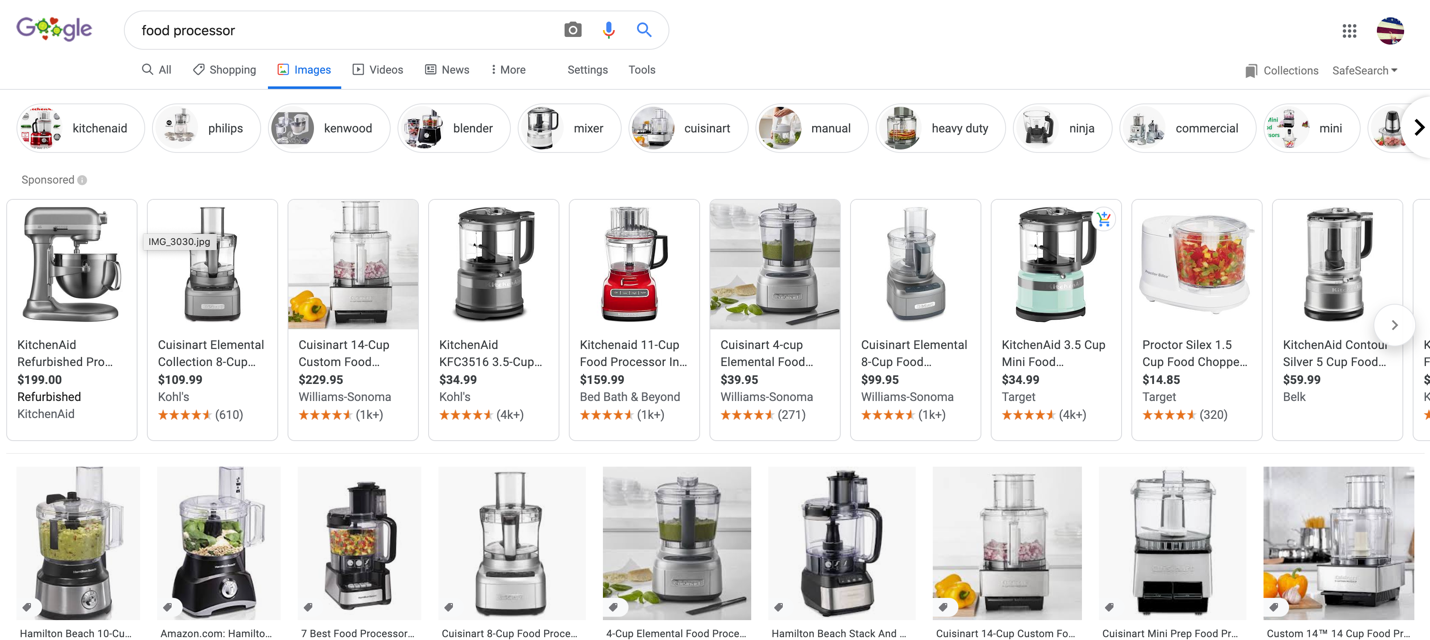
Searching for images on Google is a simple process.
Many of us can quickly find a picture of something we are searching for by performing a basic Google image search.
Google populates the results, sometimes with ads in the first row, with rows and rows of images and then links back to their respective websites.
This is the standard image search functionality that most of us are used to seeing when we’re looking for a photo on Google.
It is an extremely common search result format, that clearly layouts and categorizes various types of image results.
However, many of us often forget or underutilize Google’s advanced image search feature, which can help us all perform more refined image searches.
Below are a few methods to use advanced image search on Google to find images that you’re after, more quickly and efficiently.
Advanced Search Filters
By navigating to images.google.com, you can start to perform your standard image search.
The basic search bar appears for you to enter your query.
However, many do not know that by clicking “tools”, you can then see a few different advanced filters to help specify what you are looking for even further.
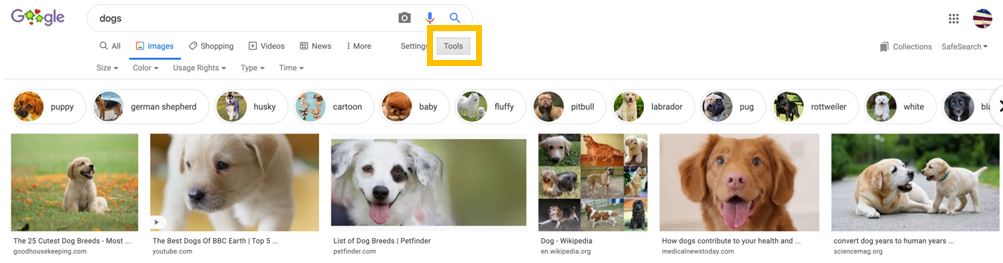
You can filter image results in the following ways:
Image Size
Here you can choose from large, medium, small, or an icon.
This can help to quickly locate an image based on the specific size you are after.
Whether it be a larger “hero” image or a smaller thumbnail, this feature can make it a speedier process to specify sizes.
Image Color
You have the option of black and white, transparent, or a specific color such as blue, red, yellow, etc.
This can help to easily narrow down an image search to pick up on any certain tones or colors you’re after.
Say you are writing a blog post on beach vacations, and want some images with light blue water, you can quickly find those using this filter.
Image Usage Rights
Labeled for reuse with modification, labeled for reuse, labeled for noncommercial reuse with modification, labeled for non-commercial reuse.
This is helpful in order to easily identify what photos are up for reuse and which ones are not.
Image Type
Options include clip art, line drawing, and GIF.
This can help to easily locate images based on animation or illustration type.
Time
Options include the past 24 hours, past week, past month, past year.
This can help to pin down more recent photos that may be more relevant, dependent on the topic you are after.
Google Advanced Image Search
Now, by navigating to Google’s Advanced Image Search, you will find that this tool uses all of the filters listed above, and then some.
If you still cannot find a specific image that you are after with the basic filters, this is a great tool to try.
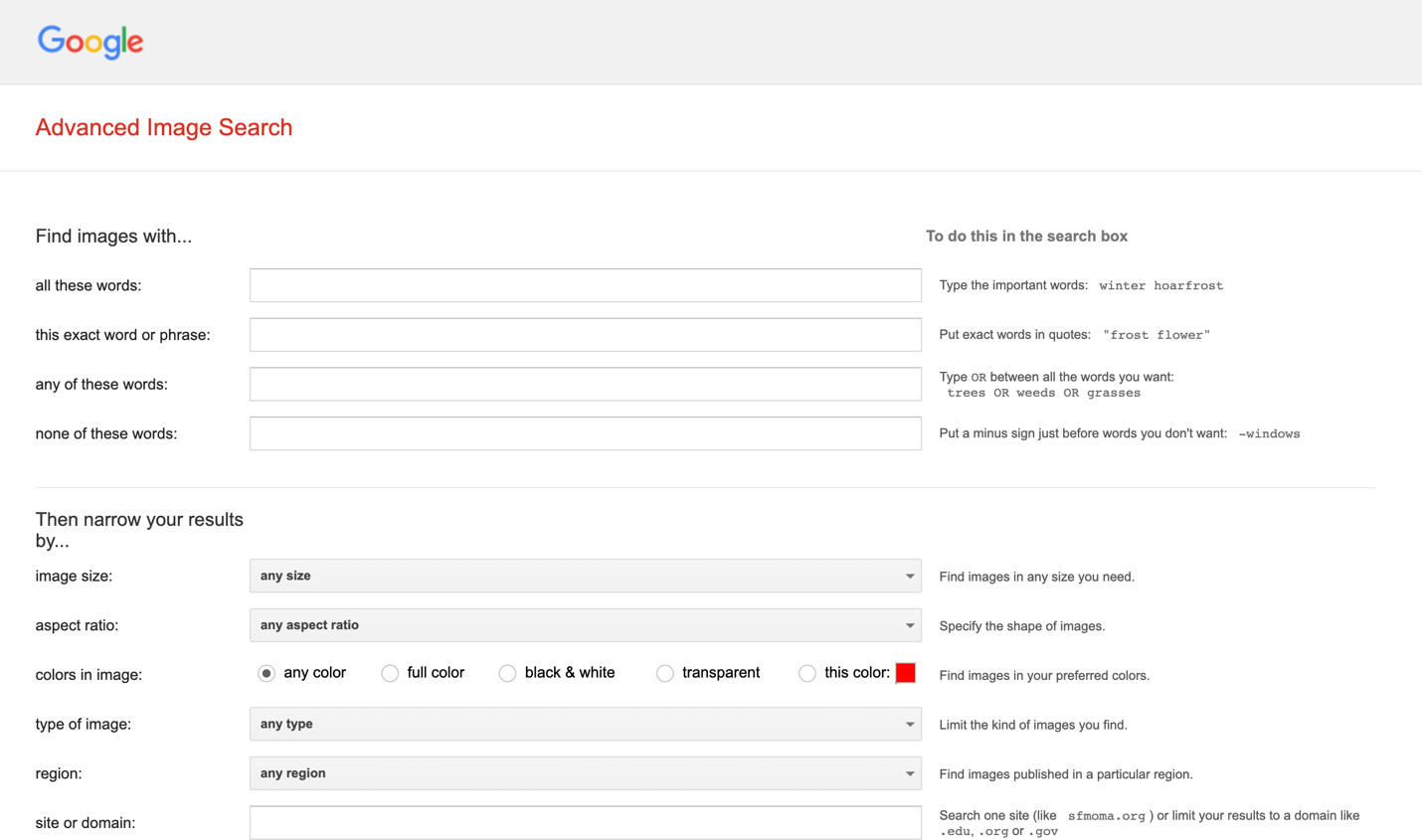
This Exact Word or Phrase
This option lets you find images after inputting multiple keywords, to narrow down and specify your search further.
This is very similar to using quotes when searching for something online.
Aspect Ratio
This feature allows you to search specifically for certain image aspect ratios.
So, if you wanted to see an image that should be wide, tall, panoramic, etc., you can find those images here.
Region
This feature allows you to see which photos are public in a specific part of the world.
This makes it easy to pin down photos from places you plan to visit, etc.
Site or Domain
Like a Google site search, use this advanced image search option to limit the results to photos from a particular website URL.
SafeSearch
Enable or disable SafeSearch to block inappropriate content.
File Type
If you are after specific file types, you can pick which image file format Google should look for (e.g., JPG, PNG, SVG).
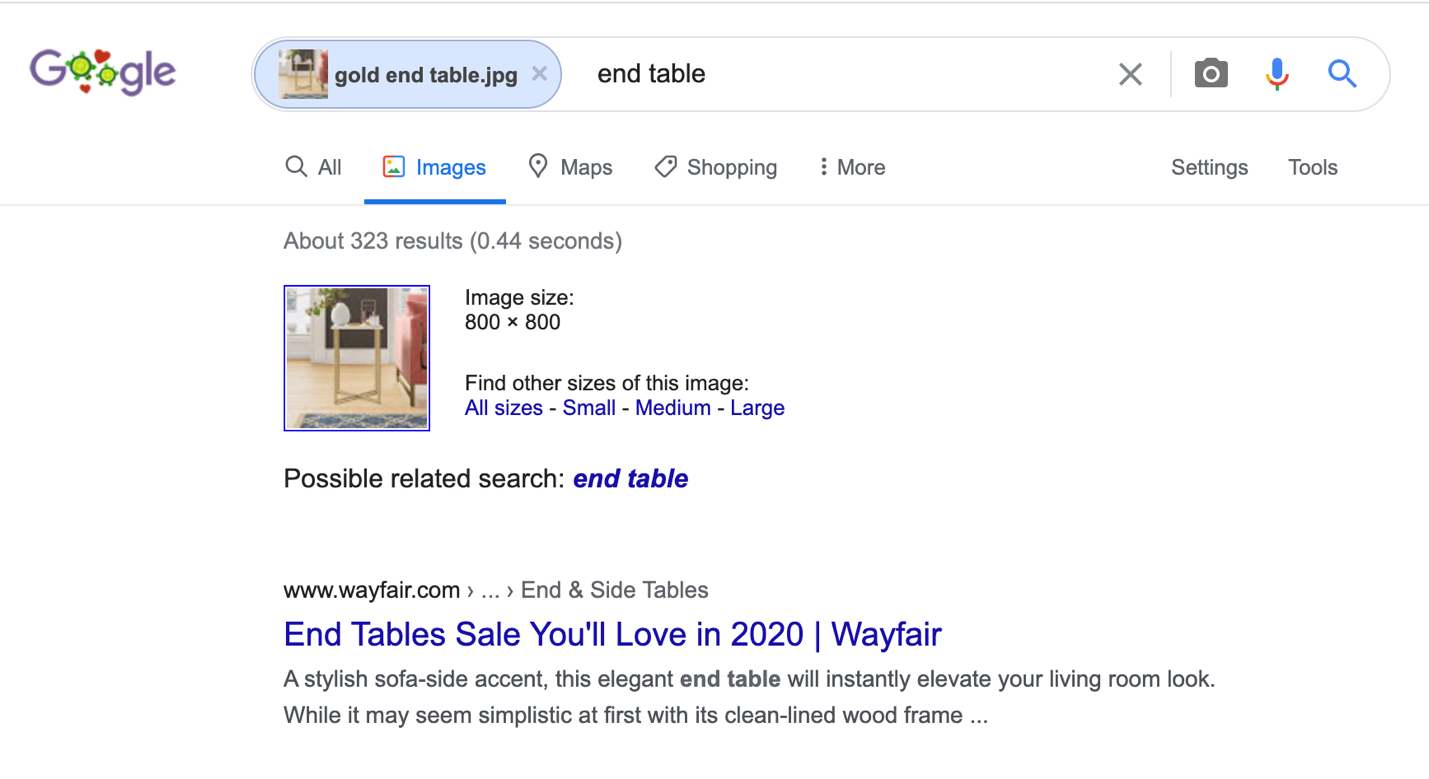
Reverse Image Search
By going to google.com and then selecting “images” in the top right corner, you are brought to Google’s reverse image search.
Now, when you select the camera icon, you can then search for other images by uploading an image.
You can either place an image URL or upload your own specific image.
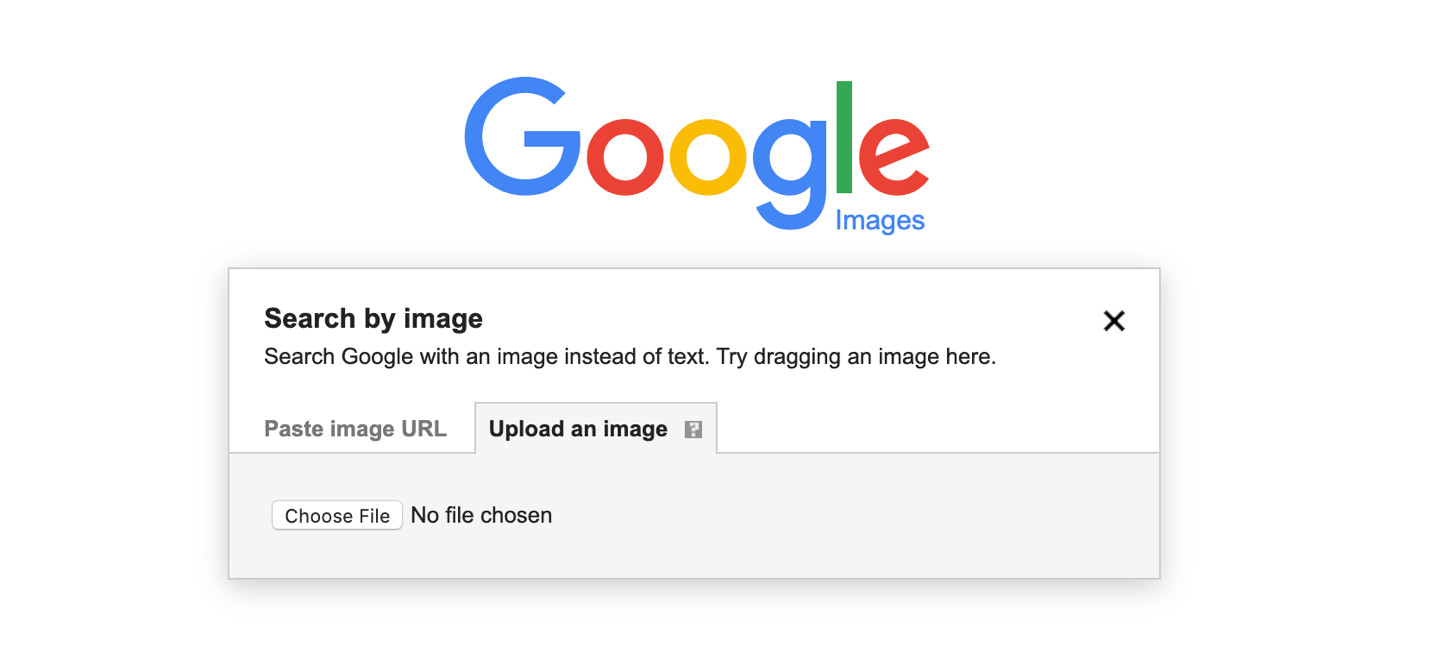
This is useful for a few different reasons.
Refine & Narrow Your Search
A reverse image search can help you find images that fit a granular set of search criteria, saving you time scrolling through hundreds of images to locate what you’re after.
It helps to refine and narrow your search, creating a better overall user experience.
Pinpoint Image Sources
Say you had saved an image of something when you were searching – for instance, an in-end table that you had been interested in.
You saved the image to your computer, however, cannot remember what website you had pulled it from.
Performing a reverse image search can help you to quickly pinpoint the source.
This can save you a lot of time and hassle, for various types of search results.
Integrate Advanced Image Search
There are billions of image searches happening every day.
Yet, many don’t know the full functionality and capabilities that Google offers for performing more robust image searches.
Utilizing these capabilities can help you save a significant amount of time, especially when searching for a specific image, or certain parameters that an image needs to meet.
The next time you’re looking for a specific image, take advantage of advanced filters and reverse image search to help you pinpoint what you’re after.
More Resources:
- How to Do Reverse Image Search on Google, Bing, Yandex & Tineye
- The 10 Best Image Search Engines
- 3 Creative Uses of Google Image Search to Boost Traffic & Acquire Links
Image Credits
All screenshots taken by author, July 2020