

Search engine optimization, in its most basic sense, relies upon one thing above all others: Search engine spiders crawling and indexing your site.
But nearly every website is going to have pages that you don’t want to include in this exploration.
For example, do you really want your privacy policy or internal search pages showing up in Google results?
In a best-case scenario, these are doing nothing to drive traffic to your site actively, and in a worst-case, they could be diverting traffic from more important pages.
Luckily, Google allows webmasters to tell search engine bots what pages and content to crawl and what to ignore. There are several ways to do this, the most common being using a robots.txt file or the meta robots tag.
We have an excellent and detailed explanation of the ins and outs of robots.txt, which you should definitely read.
But in high-level terms, it’s a plain text file that lives in your website’s root and follows the Robots Exclusion Protocol (REP).
Robots.txt provides crawlers with instructions about the site as a whole, while meta robots tags include directions for specific pages.
Some meta robots tags you might employ include index, which tells search engines to add the page to their index; noindex, which tells it not to add a page to the index or include it in search results; follow, which instructs a search engine to follow the links on a page; nofollow, which tells it not to follow links, and a whole host of others.
Both robots.txt and meta robots tags are useful tools to keep in your toolbox, but there’s also another way to instruct search engine bots to noindex or nofollow: the X-Robots-Tag.
What Is The X-Robots-Tag?
The X-Robots-Tag is another way for you to control how your webpages are crawled and indexed by spiders. As part of the HTTP header response to a URL, it controls indexing for an entire page, as well as the specific elements on that page.
And whereas using meta robots tags is fairly straightforward, the X-Robots-Tag is a bit more complicated.
But this, of course, raises the question:
When Should You Use The X-Robots-Tag?
According to Google, “Any directive that can be used in a robots meta tag can also be specified as an X-Robots-Tag.”
While you can set robots.txt-related directives in the headers of an HTTP response with both the meta robots tag and X-Robots Tag, there are certain situations where you would want to use the X-Robots-Tag – the two most common being when:
- You want to control how your non-HTML files are being crawled and indexed.
- You want to serve directives site-wide instead of on a page level.
For example, if you want to block a specific image or video from being crawled – the HTTP response method makes this easy.
The X-Robots-Tag header is also useful because it allows you to combine multiple tags within an HTTP response or use a comma-separated list of directives to specify directives.
Maybe you don’t want a certain page to be cached and want it to be unavailable after a certain date. You can use a combination of “noarchive” and “unavailable_after” tags to instruct search engine bots to follow these instructions.
Essentially, the power of the X-Robots-Tag is that it is much more flexible than the meta robots tag.
The advantage of using an X-Robots-Tag with HTTP responses is that it allows you to use regular expressions to execute crawl directives on non-HTML, as well as apply parameters on a larger, global level.
To help you understand the difference between these directives, it’s helpful to categorize them by type. That is, are they crawler directives or indexer directives?
Here’s a handy cheat sheet to explain:
| Crawler Directives | Indexer Directives |
| Robots.txt – uses the user agent, allow, disallow, and sitemap directives to specify where on-site search engine bots are allowed to crawl and not allowed to crawl. | Meta Robots tag – allows you to specify and prevent search engines from showing particular pages on a site in search results.
Nofollow – allows you to specify links that should not pass on authority or PageRank. X-Robots-tag – allows you to control how specified file types are indexed. |
Where Do You Put The X-Robots-Tag?
Let’s say you want to block specific file types. An ideal approach would be to add the X-Robots-Tag to an Apache configuration or a .htaccess file.
The X-Robots-Tag can be added to a site’s HTTP responses in an Apache server configuration via .htaccess file.
Real-World Examples And Uses Of The X-Robots-Tag
So that sounds great in theory, but what does it look like in the real world? Let’s take a look.
Let’s say we wanted search engines not to index .pdf file types. This configuration on Apache servers would look something like the below:
<Files ~ ".pdf$"> Header set X-Robots-Tag "noindex, nofollow" </Files>
In Nginx, it would look like the below:
location ~* .pdf$ {
add_header X-Robots-Tag "noindex, nofollow";
}
Now, let’s look at a different scenario. Let’s say we want to use the X-Robots-Tag to block image files, such as .jpg, .gif, .png, etc., from being indexed. You could do this with an X-Robots-Tag that would look like the below:
<Files ~ ".(png|jpe?g|gif)$"> Header set X-Robots-Tag "noindex" </Files>
Please note that understanding how these directives work and the impact they have on one another is crucial.
For example, what happens if both the X-Robots-Tag and a meta robots tag are located when crawler bots discover a URL?
If that URL is blocked from robots.txt, then certain indexing and serving directives cannot be discovered and will not be followed.
If directives are to be followed, then the URLs containing those cannot be disallowed from crawling.
Check For An X-Robots-Tag
There are a few different methods that can be used to check for an X-Robots-Tag on the site.
The easiest way to check is to install a browser extension that will tell you X-Robots-Tag information about the URL.
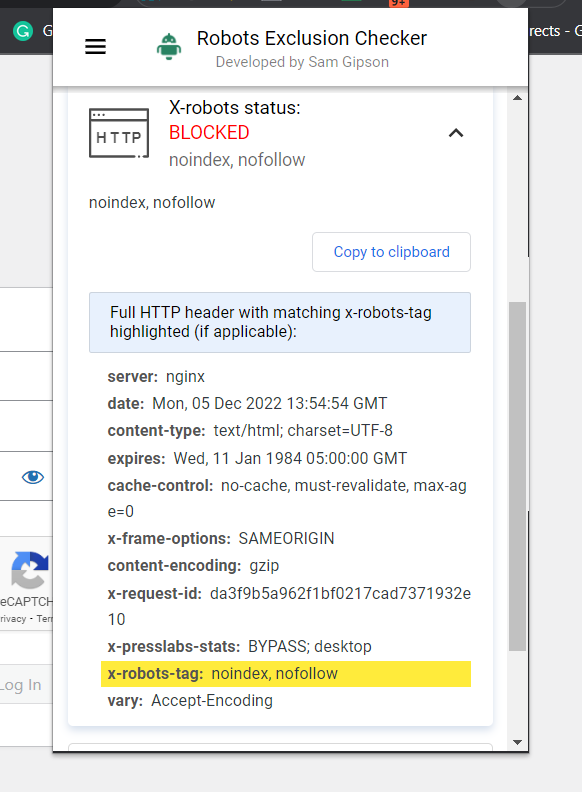
Another plugin you can use to determine whether an X-Robots-Tag is being used, for example, is the Web Developer plugin.
By clicking on the plugin in your browser and navigating to “View Response Headers,” you can see the various HTTP headers being used.

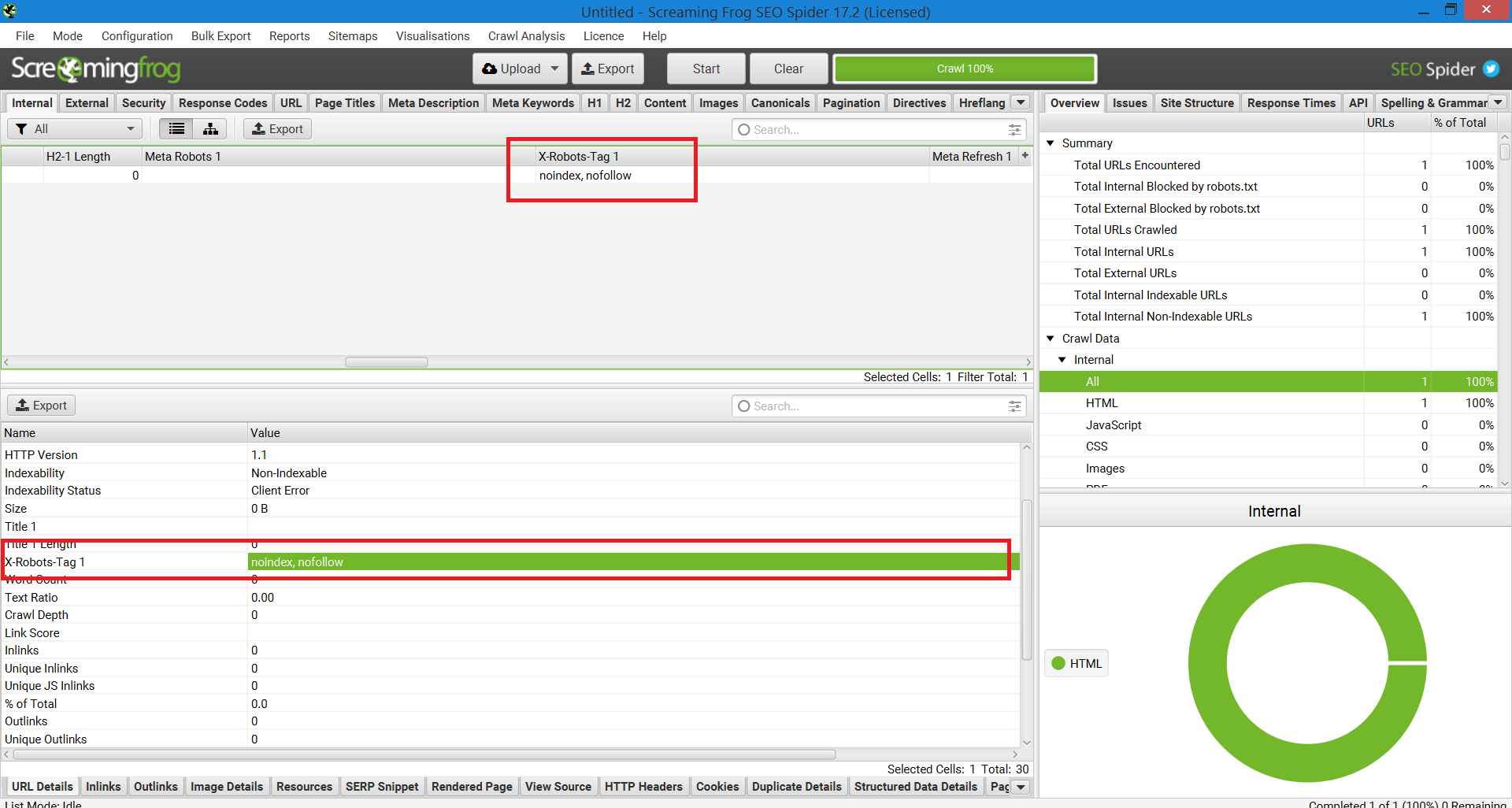
Another method that can be used for scaling in order to pinpoint issues on websites with a million pages is Screaming Frog.
After running a site through Screaming Frog, you can navigate to the “X-Robots-Tag” column.
This will show you which sections of the site are using the tag, along with which specific directives.
Using X-Robots-Tags On Your Site
Understanding and controlling how search engines interact with your website is the cornerstone of search engine optimization. And the X-Robots-Tag is a powerful tool you can use to do just that.
Just be aware: It’s not without its dangers. It is very easy to make a mistake and deindex your entire site.
That said, if you’re reading this piece, you’re probably not an SEO beginner. So long as you use it wisely, take your time and check your work, you’ll find the X-Robots-Tag to be a useful addition to your arsenal.
More Resources:
- Google Gives Sites More Indexing Control With New Robots Tag
- 6 Common Robots.txt Issues & And How To Fix Them
- Advanced Technical SEO: A Complete Guide
Featured Image: Song_about_summer/Shutterstock