

Many things have changed since 2010 when SEO was more concerned with getting as many backlinks as you could and including as many keywords as possible.
In 2021, the focus has shifted to understanding intent and behavior, and the context – semantics – behind them.
Today, search engine understanding has evolved, and we’ve changed how we optimize for it as a result. The days of reverse-engineering content that ranks higher are behind us, and identifying keywords is no longer enough.
Now, you need to understand what those keywords mean, provide rich information that contextualizes those keywords, and firmly understand user intent.
These things are vital for SEO in an age of semantic search, where machine learning and natural language processing are helping search engines understand context and consumers better.
In this piece, you’ll learn what semantic search is, why it’s essential for SEO, and how to optimize your content for it.
What Is Semantic Search?
Semantic search describes a search engine’s attempt to generate the most accurate SERP results possible by understanding based on searcher intent, query context, and the relationship between words.

This is important as:
- People say things and query things in different ways, languages, and tones.
- Search queries can be ambiguous in nature.
- There is a need to understand the relationships between words.
The relationships between entities and personal choice and relationships are also very important.
Google spends lots of money on patents related to this. This works when a user queries something like [top 10 movies of 2021] and Google returns several options/websites for the user to visit.
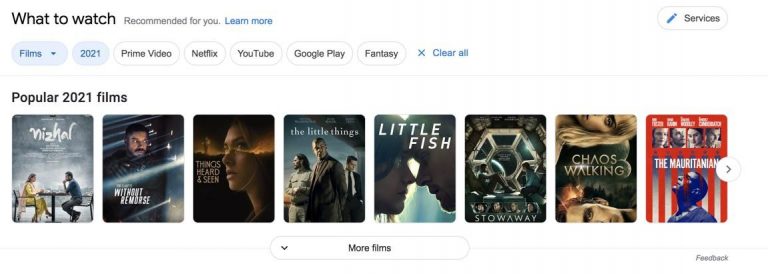
Bill Slawski explains more in this post.
In layman’s terms, semantic search seeks to understand natural language the way a human would.
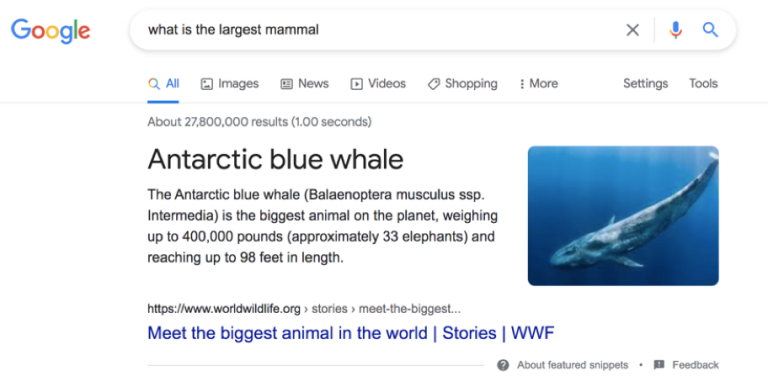
For example, if you asked your friend, “What is the largest mammal?” and then followed that question up with “How big is it?” your friend would understand that “it” refers to the largest mammal: a blue whale.
Before 2013, however, search engines wouldn’t understand the context of the second question.
Instead of answering “How big is a blue whale,” Google would seek to match the specific keywords from the phrase “How big is it?” and return webpages with those exact keywords.
Today, you see a different result with a featured snippet and understanding of the context behind the question with extra information.
Semantic search also allows Google to distinguish between different entities (people, places, and things) and interpret searcher intent based on a variety of factors, including:
- User search history.
- User location.
- Global search history.
- Spelling variations.
This all helps Google in its goal to provide a better experience for its users by delivering quality and giving preference to relevant content results.
Semantic Search: A Brief History
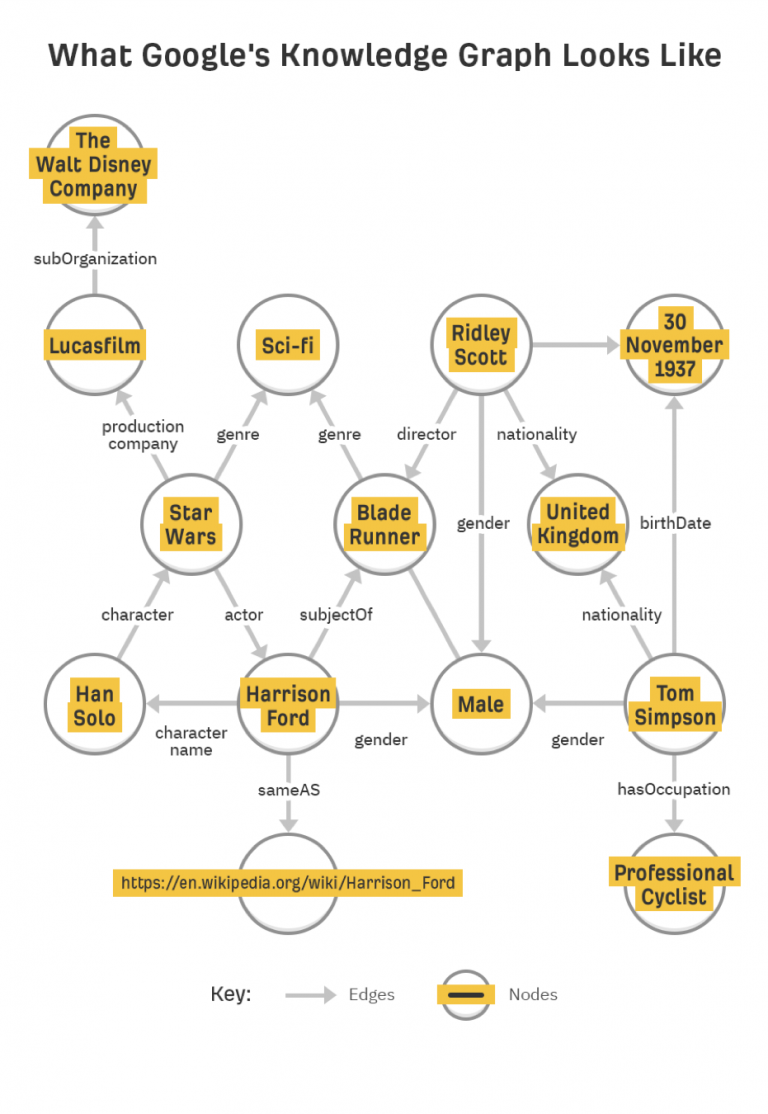
The Knowledge Graph
Introduced in 2012, the Knowledge Graph was Google’s first step in developing the importance of entities and context over strings of keywords – or, as Google phrased it, “things, not strings.”
The Knowledge Graph set the stage for the large-scale algorithmic changes to come.
As a massive database of public information, the Knowledge Graph collected information considered public domain (e.g., distance to the moon, Abraham Lincoln’s presidential term, the cast of “Star Wars,” etc.) and the properties of each entity (people have birthdays, siblings, parents, occupations, etc.).
Hummingbird
Google’s Hummingbird update, rolled out in 2013, is arguably the beginning of the semantic search era as we know it today.
Hummingbird uses NLP to ensure that “pages matching the meaning do better, rather than pages matching just a few words.” In essence, this means that pages that better match searcher context and intent will rank better than pages that repeat context-less keywords ad nauseam.
RankBrain
In 2015, Google launched RankBrain, a machine learning system that’s both a ranking factor and a smart query analysis AI.
RankBrain, like Hummingbird, seeks to understand the user intent behind queries. The critical difference between them is RankBrain’s machine-learning component.
RankBrain is always learning, analyzing the best-performing search results, and looking for similarities between the pages that users find valuable.
As a result, RankBrain may deem a page to be a “good response” to a query even if it doesn’t contain exact words from the question.
BERT
Introduced in 2019, BERT (Bidirectional Encoder Representations from Transformers) was introduced by Google. This focuses on further understanding intent and conversation search context.
BERT allows users to more easily find valuable and accurate information.
According to Google, this represented the most significant leap forward in the past five years and one of the greatest in search history. It gave marketers direction to work more with longtail queries and phrases with more than three words and ensure content addresses users’ questions.
It also meant that SEO professionals had to shift their focus on writing for humans with clear and concise content that is easy to understand.
How Does Semantic Search Impact SEO?
Users Turn to Voice Search
Semantic search has evolved in large part due to the rise of voice search.
Mobile voice commands are now commonplace and using voice commands on devices other than is already “frequent” or “very frequent” among 33% of high-income households.
Optimizing for voice search is very different from traditional SEO because you must immediately get to the point (for intent-based searches) and keep your content much more conversational.
What You Can Do
Create content that clearly and concisely answers a common query at the top of the page before delving into more specific details.
Make sure to use structured data to help search engines understand your content and context.
For example, a sporting goods retailer might make a checklist of what to take on a day hike, followed by information about local wildlife, fishing and hunting regulations, and contact information for emergency services.
Focus Shifts from Keywords to Topics
It’s time to stop creating content around keywords.
Instead, you should be thinking about broad topics in your niche that you can cover in-depth.
The goal here is to create comprehensive, original, and high-quality resources.
What You Can Do
Instead of creating dozens of short, disparate pages, each with its own topic, consider creating “ultimate guides” and more comprehensive resources that your users will find valuable.
Searcher Intent Becomes a Priority
One of the best approaches to keyword targeting isn’t actually keyword targeting so much as it is intent targeting.
By examining the queries that lead people to your website, you’ll be able to come up with a group of topics ideal for building content around.
What You Can Do
Make a list of keywords and separate them by user intent.
For example, the queries [iPhones vs. Android battery life] or [compare Apple and Samsung phones] both clearly fall under the umbrella intent of [compare smartphones].
In contrast, [where to buy iPhone 12] and [best deals for Samsung Galaxy] both communicate an intent to purchase.
Once you understand searcher intent, start creating content that directly addresses their intent instead of creating content around individual keywords or broad topics.
Technical SEO Matters Just as Much as Content
Even with Google’s transition from string to things, the algorithm isn’t yet smart enough to derive meaning or understanding on its own.
You still need to optimize your site and help Google understand your content.
Keywords
Yes, keywords still matter. Use a content analysis tool to mine for common questions and related long-tail keywords that you can incorporate into your content. Include keywords in your title tags, URL, body, header tags, and meta tags, as long as it fits naturally.
Link building
Authoritative backlinks remain one of the most important ranking signals. Prioritize content that naturally attracts links. Also, don’t forget to use proper internal linking structures to develop deep links to other valuable content you’ve created.
Structured data
Use Schema markup to help customers find your business and search engines index your site. You can add more detail using review markup and organization markup too.
Errors
Try to eliminate redirects whenever possible, only relying on 301 redirects for missing pages. You should have no more than one redirect per page. Also, use rel=canonical tags for different versions of your website.
Site speed
Minify resources, compress images, leverage browser caching, and follow Google’s checklist for optimizing your website’s speed.
Optimize site structure
Maintaining a logical site structure will help search engines index your website and understand the connection between your content. Logical site structures also improve UX by providing users with a logical journey through your website.
Focus Shifts to User Experience
User satisfaction should be guiding all of our SEO efforts in an age of semantic search.
Google cares about user satisfaction, and they are continuously fine-tuning their algorithm to understand better and satisfy searchers.
SEO professionals should be focusing on UX, too.
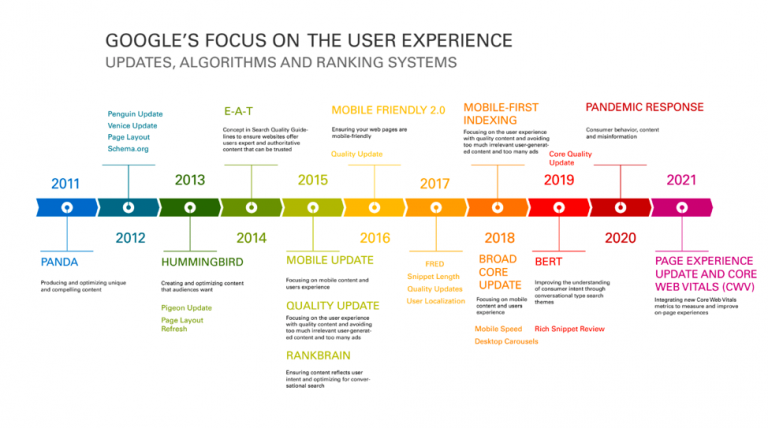
Read more on Google and the User Experience here.
What You Can Do
Improve page speed as much as possible, make sure your mobile site is optimized (especially now that Google prioritizes mobile sites for indexing), and keep an eye on metrics like bounce rate and session duration.
Whenever you think you can find something that can be improved, run A/B experiments to see if you can boost engagement.
Conclusion
Understanding how Google understands intent in intelligent ways is essential to SEO. Semantic search should be top of mind when creating content. In conjunction, do not forget about how this works with Google E-A-T principles.
Mediocre content offerings and old-school SEO tricks simply won’t cut it anymore, especially as search engines get better at understanding context, the relationships between concepts, and user intent.
Content should be relevant and high-quality, but it should also zero in on searcher intent and be technically optimized for indexing and ranking.
If you manage to strike that balance, then you’re on the right track.
More SEO Resources:
- How People Search: Understanding User Intent
- What Is Latent Semantic Indexing & Why It Won’t Help Your SEO
- Core Web Vitals: A Complete Guide
Image Credits
Image 4: Ahrefs
All screenshots taken by author, June 2021
