


Search Engines and Block Analysis with Image Retrieval
What are some of the methods to combat the issues with linkage data, that search engines often depend upon for ranking one page over the next? If you’re reading this, you most probably know all too well about how sites exchange links with each other, how people buy text links and all the spam found in blogs and other open sites. So how does a search engine weed out the ‘meaningless’ or ‘less important’ links from a Web page?
One answer is something called “block analysis’ and there is an excellent thread going on at SEW Forums named Block Analysis 101. I will warn you, it gets a bit technical. Let me pull one concept out of the thread, and hopefully come back to this thread at a later time to discuss the rest.
How does a search engine look at the “blocks”, “passages” or location of the content on the page as would a human? With the use of CSS, it can be very hard for an engine to understand which content goes with which links. The goal is for the engines to look at a page, understand the blocks within the page and then assign appropriate weights to the content and links based on which ‘block’ the content and links are found.
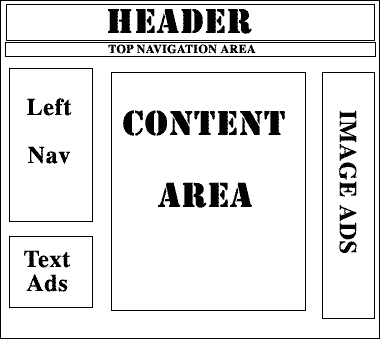
For example, take a look at the image below of a typical content site. You will see how I separated out the major components of a page’s layout. Removing all the fluff, when a human finds the page he or she is looking for, they want to simply focus on the middle portion of the page, “content area”. And one would expect that the links and content within the ‘content area’ is the most relevant to what this page is discussing. If a link is found within that section, it is sometimes (we are now finding contextual based ads within the content of the pages, dynamically changing words in passages, based on a keyword match, to link to an advertisers site) good to assume that the link is important, in fact, it is probably one of the most important links on the whole page. Search engines know that.
Columnist Barry Schwartz is the Editor of Editor of Search Engine Roundtable and President of RustyBrick, Inc., a Web services firm specializing in customized online technology that helps companies decrease costs and increase sales.
