

In a recent webmaster hangout, Google’s John Mueller was asked if Google’s search feedback form can be used to hurt individual websites. Mueller’s response was unambiguous and also informative about how Googles search teams use the information gathered from search feedback.
Nuance: What is Search Feedback?
At the bottom of every search results page (SERPs) is a link with the anchor text, Send feedback.
Clicking that link spawns a pop up form that allows users to send feedback about a search result.
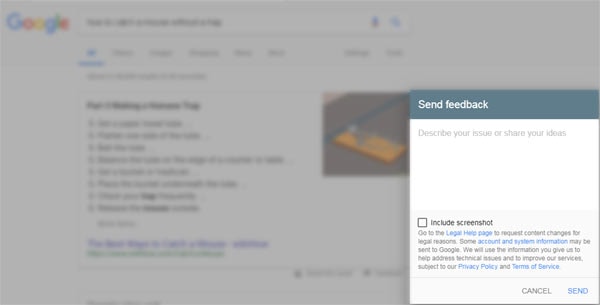
The form contains a disclosure that warns users that their system information may be sent to Google.
Presumably they are recording your browser and IP data so they can identify malicious reports but also to record statistical data related to geography, computer OS and so on. This kind of data can be useful for tracking down bugs.
Question About Feedback Form Sabotage
A web publisher suggested that he was aware that their competition was using Google’s own feedback form to file negative reports about his company’s websites. Here is the question:
“…we’re an independent company, we go against conglomerates that are in the billions, worth millions, they have a lot at stake.
They use the feedback, we know this… We know they use the feedback section. We know they use their interns… to denigrate us.
Does that have any effect on ranking and how one is trusted or rated in any way?”
Nuance: About John Mueller’s Answers
There are some answers where John Mueller tends to use filler words such as “well” or “Uhm” as a way to pause his speaking while thinking through his answers.
John Mueller’s response was immediate and without hesitation. This seemed to indicate that this was a topic he was confident about.

Here is Mueller’s response:
“No, no… That’s something that goes to the search team, to the search quality team, to the user experience people, and they take this feedback in a way to better understand… what people’s thoughts are and what kind of content they would like to see in individual situations.”
John Mueller was clear about this point. The answer is no, the feedback form can not be used to negatively hurt the rankings of a website.
How is the Feedback Form Used by Google?
Mueller then went on to discuss how Google uses the search feedback form.
“So that’s something that’s usually more of a longer process and more of something like, “Oh, we’ve seen people complain about… amp pages because they don’t like them or they don’t like the logo… we’ve seen lots of people complain about this over time so maybe we should change something slightly there.”
But on the basis of individual sites that’s not something that we would use that for.
So it’s really a matter of like this is a general trend… and they’re not focusing on one specific site but rather like this whole different area that we’re kind of getting wrong in search and we get feedback from all kinds of people on that general area.
And because of that we should figure out… some approach that we can do to make it easier to show more relevant results to the bigger group of people.”

Nuance: Feedback Form and Quality Control
That last part about showing more relevant results to the bigger group of people may be a reference to how Google’s algorithm is focused on satisfying the most amount of people at the top of the SERPs then moving on to the next largest group who may be satisfied with a different kind of search result. That’s related to user intent.
what John Mueller appears to be saying is that search results feedback does not impact individual sites. But rather, it feeds into the process of quality control in aggregate. The purpose of this quality control is to identify trends of why a search result is not satisfying the most amount of people.
Mueller’s response confirms that the Search Results Feedback Form cannot be used to negatively affect reported sites.
Watch the question and answer directly in Google’s Webmaster Hangout
Images by Shutterstock, Modified by Author
Screenshots by Author
