



During a recent analysis, I ended up reviewing two sites that had very different site structure issues. Both websites held great content, but were structuring their content in a way that was causing problems SEO-wise. These “hide and seek” problems are inhibiting the sites in question from ranking well for target keywords, which is cutting into new visitors, advertising dollars, and sales. Note, although I’ll explain the problems I encountered in detail, I’m not going to list the websites. The point of my post is to simply highlight site structure issues so you can avoid them when working on your own websites.
The first problem I’m going to explain is present on a relatively large website, and is creating massive amounts of duplicate content. I can’t say if the issue was a case of SEO compromise or if they truly don’t know the problem is occurring. But they will know it’s occurring at some point… This is why I always explain that you should fight for SEO during planning meetings.
The second example I’m going to explain is definitely more benign, but is hiding a lot of quality content from the engines. This type of problem is typically implemented by business owners, designers, or developers that don’t know the SEO impact of what they are implementing. They might think the solution is great for usability, but never realize it’s decreasing the effectiveness of their SEO efforts.
OK, enough with the introduction! Let’s take a look at two examples of site structure issues that you should avoid:
Site Structure Problem #1: Producing Infinite Amounts of Duplicate Content
We all know that duplicate content can be a huge problem SEO-wise. And that’s especially the case with websites that hold a lot of content. For example, a site that houses tens of thousands of pages could easily drive Google or Bing to hundreds of thousands of pages of duplicate content (if the site isn’t structured properly). And when duplicate content can dilute your SEO power and force the bots into an endless loop of crawling duplicate pages, the consequences could be serious.
Sometimes duplicate content could be caused by how the site is programmed, or by a CMS glitch, and other times it’s caused by human error during the Information Architecture (IA) planning. As I drilled through a site recently, I was amazed at what I found. Unfortunately, the site structure is resulting in an unlimited amount of duplicate content, and is already causing serious SEO problems. Right now, there are tens of thousands of pages of duplicate content, and that’s going to grow quickly and get completely out of control.
How About This Musician, And This Musician, And This Musician, And This Musician?
The site in question provides information about local musicians, and lots of them. Instead of creating a canonical musician page, this website creates a new musician page every time that person or band is playing somewhere (at different venues and on different dates). The new musician pages are identical to each other, with exactly the same content, images, etc. (word for word). The only addition is a link to buy tickets for a specific performance (if you can purchase tickets online for that performance). And this happens even if the musician has multiple performances at the same venue per day (like a morning and then afternoon performance). Yes, two new duplicate pages would be created… The on-page optimization is also exactly the same for each of the pages, including title tag, meta description, etc.
There are new URL’s for every new musician page, which is creating an unlimited number of new pages of duplicate content per musician. Add thousands of musicians to the site (across regions), and you can start to see the severe duplicate content problem that the site is facing. Technically, each musician could have an infinite number of duplicate pages as they hold new performances at new venues at different times. In addition, the site is archiving all performance pages (the duplicate pages). A quick check of one musician showed 1120 pages indexed, all containing the same exact content.
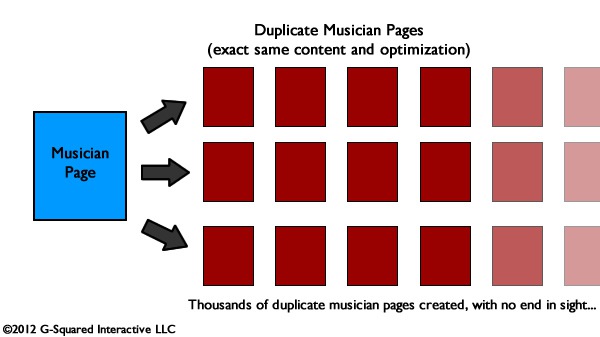
What About Canonical Signs to the Engines?
Several of you are probably wondering if the site is using the canonical URL tag on each additional musician page, pointing back to the original musician page. Well, they are using the canonical URL tag, but it’s implemented incorrectly… They have the canonical URL tag on each page of the site that points to the current page (the duplicate page) as the canonical URL. That doesn’t help at all… In order to help the situation, the canonical URL tag on each duplicate page should point to the original, canonical musician page.
“Better Than Canonical”
And by the way, the canonical URL tag isn’t always the perfect solution for dealing with something like this. Duane Forrester from Bing recently wrote a post titled “Better Than Canonical” explaining that Bing still has to use a lot of resources crawling additional content, even when the canonical URL tag is used. As a result, you can waste crawl bandwidth assigned to a website. As an alternative, he mentioned using the URL Normalization feature in Bing Webmaster Tools. Note, Google Webmaster Tools also has functionality for handling site parameters.
A Solution:
Using those features is definitely a solution, but a better solution is making sure you don’t create that much duplicate content to begin with! In my post last week about SEO and redesigns, I mentioned that having SEO present during the brainstorming stages of a redesign or website development project could nip problems like this in bud. That’s exactly what this site needed.
There are several ways you could address the duplicate content situation for this site, but I’ll just focus on one here. Instead of creating new, duplicate pages for every musician by performance, the website could have one canonical musician page that holds a wealth of information about that musician (and is the base page for the musician at hand). Then they could link to a page that holds all performances for the musician. That new “performances page” could be the canonical performance page for that musician, and it could always be updated with the latest performance information.
They could also create local venue pages so users could easily find all performances (for each musician) for a given location. The point is that they can create a logical site structure for musicians, venues, and performances without creating massive amounts of duplicate content. Again, there are several ways they could structure the site better, and this is just one path they could go down.
SEO-wise, they could work to have the canonical musician page ranking for musician-related keywords, while the performances page could rank well for performance-related keywords. Then they could have the venue page ranking for musician/location related keywords. And the engines will love them for not driving their bots to hundreds of thousands of duplicate pages… Note, you could easily start to expand this method to create unique pages for other musician-related information.
Site Structure Problem #2: Anchors and Hash Symbols
The second site structure issue I came across last week was on the opposite end of the content spectrum. A website focused on art with unique and valuable content was using anchors (via hash symbols) to break up various categories and subcategories of artwork. So, instead of hundreds of pages of optimized content, the website had 13 pages indexed. Yes, just 13.
The site linked to the top-level art categories just fine. But once you hit those pages, the site started using anchors when linking to extremely important subcategories (by dynamically loading more content). The core problem with this technique is that the engines ignore anything after the hash (the pound sign). The engines view the hash symbol as an anchor in html, which is a way to jump users to additional content within the same page. So, if anything after the hash symbol is ignored by the engines, and that’s how you are loading additional content, then that content might as well not exist SEO-wise. Running a simple site: command on the website revealed that was the case.
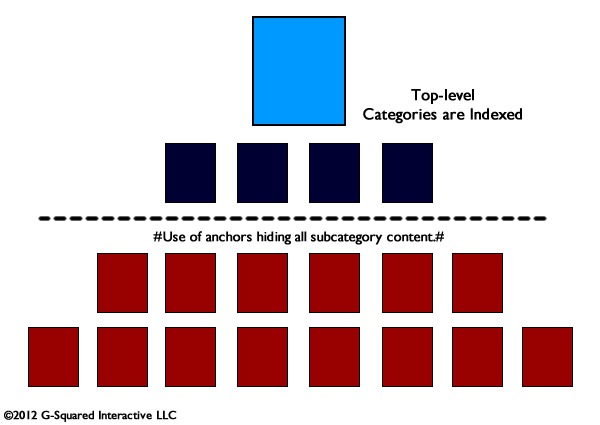
Searching for the subcategories on the site returned nothing in the search engines. None of that content is indexed, and the website obviously doesn’t rank for those keywords. Unfortunately, this site will never rank well for important subcategories that prospective customers are searching for, even though it holds extremely high quality, unique content. The good news is that the fix is pretty straight forward…
A Solution:
The site should stop using anchors to present categories and subcategories. The site owners should create unique URL’s that hold each category and subcategory, and optimize each page based on keyword research. Then they should provide a robust text navigation that enables both users and search engine bots to find that content. The anchor technique is like a silent killer of SEO because unless you look for the problem SEO-wise (like during an audit), you will never know it’s hiding content. Again, this is why having SEO involved during any site changes or additions can help avoid problems like this.
Summary – Avoid Site Structure Issues, Avoid SEO Problems
There you have it. Two examples of site structure issues that are hampering the websites I analyzed. Although they are on opposite ends of the spectrum, each issue can be extremely problematic. On the one hand, I covered how creating infinite amounts of duplicate content could cause the search engine bots to screech to a halt, while the heavy use of anchors could hide important content from the engines. It’s a dangerous game of hide and seek.
The key takeaway is that you shouldn’t play hide and seek with the search engines. You should work on creating a clean and crawlable structure that leads users and the search engine bots to unique and valuable content. After you accomplish that goal, you can play “Find and Find” versus “Hide and Seek”. 🙂
Image Credit: mediaphotosmediaphotos / iStockphoto
