



When optimizing our websites for crawlability, our main goal is to make sure that search engines are spending their time on our most important pages so that they are regularly crawled and any new content can be found.
Each time Googlebot visits your website, it has a limited window in which to crawl and discover as many pages and links on your site as possible. When that limit is hit, it will stop.
The time it takes for your pages to be revisited depends on a number of different factors that play into how Google prioritizes URLs for crawling, including:
- PageRank.
- XML sitemap inclusion.
- Position within the site’s architecture.
- How frequently the page changes.
- And more.
The bottom line is: your site only gets Googlebot’s attention for a finite amount of time with each crawl, which could be infrequent. Make sure that time is spent wisely.
It can be hard to know where to start when analyzing how well-optimized your site is for search engine crawlers, especially when you work on a large site with a lot of URLs to analyze, or work in a large company with a lot of competing priorities and outstanding SEO fixes to prioritize.
That’s why I’ve put together this list of top-level checks for assessing crawl hygiene to give you a starting point for your analysis.
1. How Many Pages Are Being Indexed vs. How Many Indexable Pages Are There on the Site?
Why This Is Important
This shows you how many pages on your site are available for Google to index, and how many of those pages Google was actually able to find and how many it determined were important enough to be indexed.
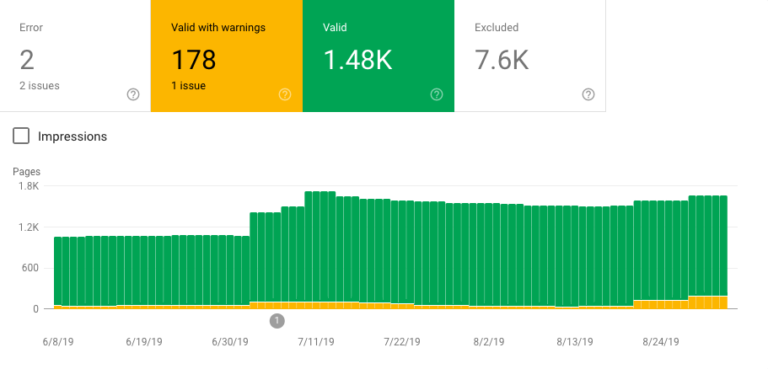
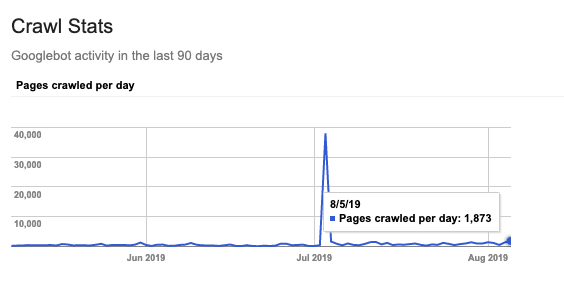
2. How Many Pages Are Being Crawled Overall?
Why This Is Important
Comparing Googlebot’s crawl activity against the number of pages you have on your site can give you insights into how many pages Google either can’t access, or has determined aren’t enough of a priority to schedule to be crawled regularly.
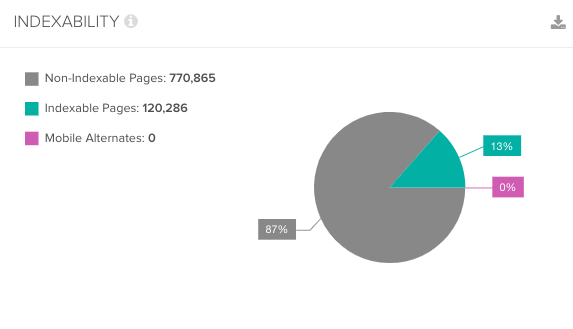
3. How Many Pages Aren’t Indexable?
Why This Is Important
Spending time crawling non-indexable pages isn’t the best use of Google’s crawl budget. Check how many of these pages are being crawled, and whether or not any of them should be made available for indexing.
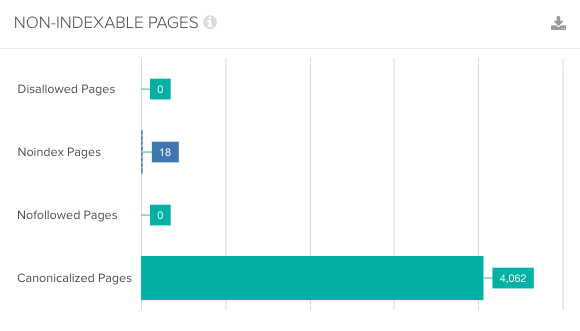
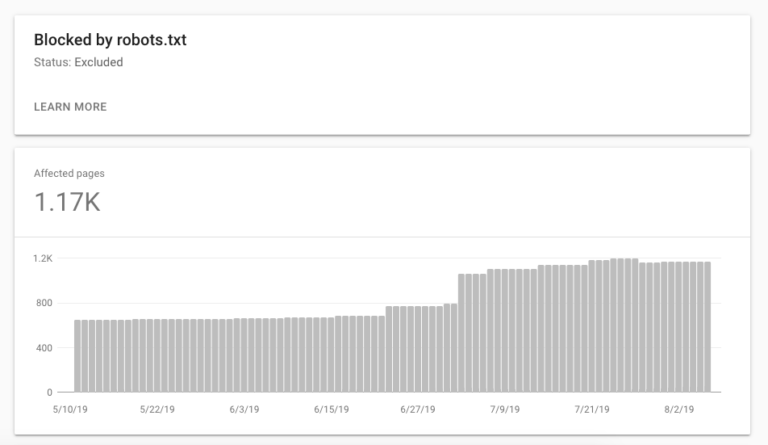
4. How Many URLs Are Being Disallowed from Being Crawled?
Why This Is Important
This will show you how many pages you are preventing search engines from accessing on your site. It’s important to make sure that these pages aren’t important for indexing or for discovering further pages for crawling.
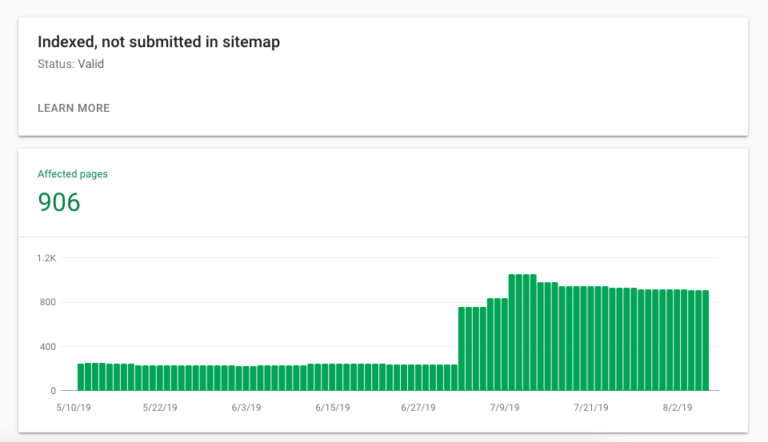
5. How Many Low-Value Pages Are Being Indexed?
Why This Is Important
Looking at which pages Google has already indexed on your site gives an indication into the areas of the site that the crawler has been able to access.
For example, these might be pages that you haven’t included in your sitemaps as they are low-quality, but have been found and indexed anyway.
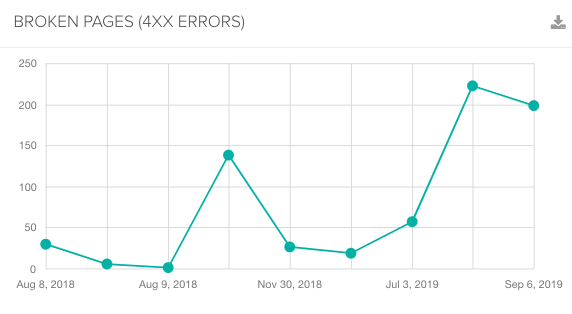
6. How Many 4xx Error Pages Are Being Crawled?
Why This Is Important
It’s important to make sure that crawl budget isn’t being used up on error pages instead of pages that you want to have indexed.
Googlebot will periodically try to crawl 404 error pages to see whether the page is live again, so make sure you use 410 status codes correctly to show that pages are gone and don’t need to be recrawled.
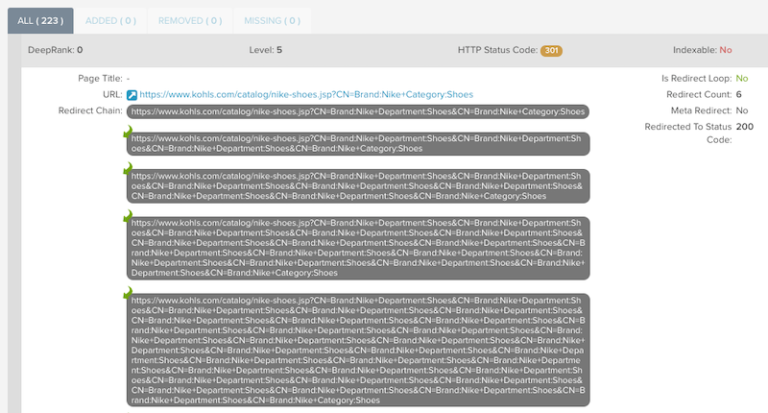
7. How Many Internal Redirects Are Being Crawled?
Why This Is Important
Each request that Googlebot makes on a site uses up crawl budget, and this includes any additional requests within each of the steps in a redirect chain.
Help Google crawl more efficiently and conserve crawl budget by making sure only pages with 200 status codes are linked to within your site, and reduce the number of requests being made to pages that aren’t final destination URLs.
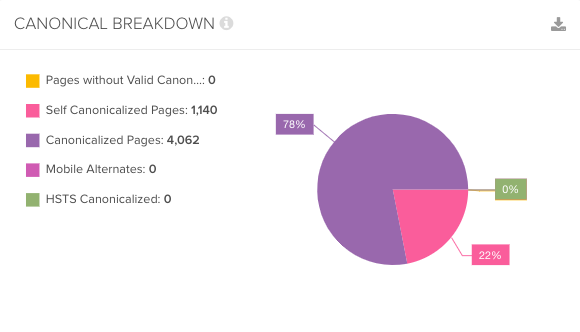
8. How Many Canonical Pages Are There vs. Canonicalized Pages?
Why This Is Important
The number of canonicalized pages on your site gives an indication into how much duplication there is on your site. While canonical tags consolidate link equity between sets of duplicate pages, they don’t help crawl budget.
Google will choose to index one page out of a set of canonicalized pages, but to be able to decide which is the primary page, it will first have to crawl all of them.
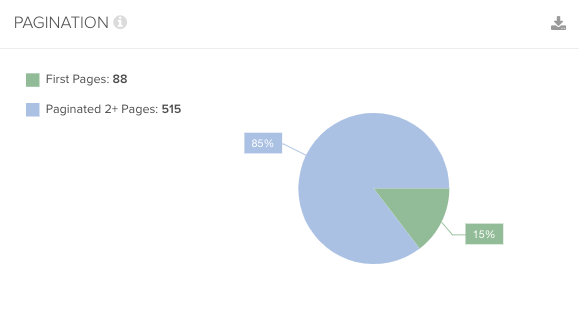
9. How Many Paginated or Faceted Pages Are Being Crawled?
Why This Is Important
Google only needs to crawl pages that include otherwise undiscovered content or unlinked URLs.
Pagination and facets are usually a source of duplicate URLs and crawler traps, so make sure that these pages that don’t include any unique content or links aren’t being crawled unnecessarily.
As rel=next and rel=prev are no longer supported by Google, ensure your internal linking is optimized to reduce reliance on pagination for page discovery.
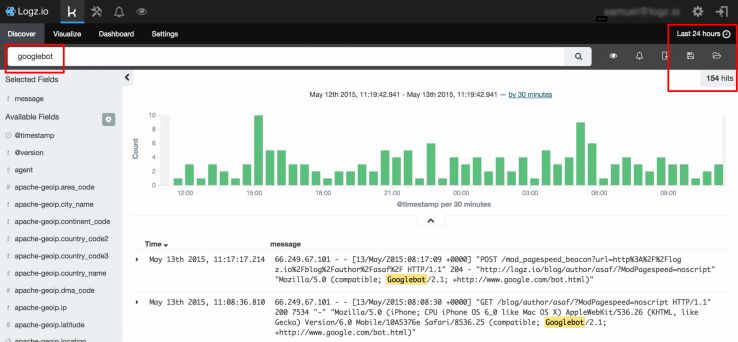
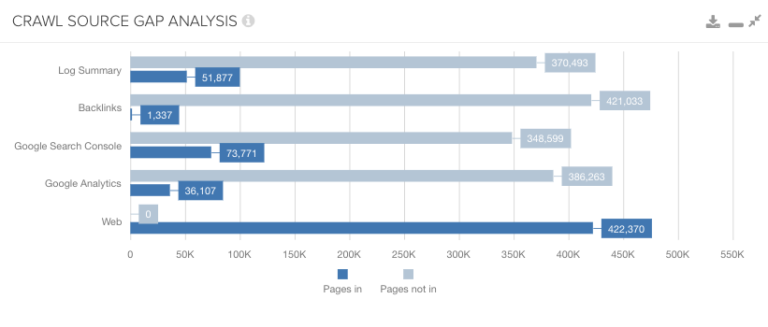
10. Are There Mismatches in Page Discovery Across Crawl Sources?
Why This Is Important
If you’re seeing pages being accessed by users through your analytics data that aren’t being crawled by search engines within your log file data, it could be because these pages aren’t as discoverable for search engines as they are for users.
By integrating different data sources with your crawl data, you can spot gaps where pages can’t be easily found by search engines.
Google’s two main sources of URL discovery are external links and XML sitemaps, so if you’re having trouble getting Google to crawl your pages, make sure they are included in your sitemap if they’re not yet being linked to from any other sites that Google already knows about and crawls regularly.
To Sum Up
By running through these 10 checks for your websites that you manage, you should be able to get a better understanding of the crawlability and overall technical health of a site.
Once you identify areas of crawl waste, you can instruct Google to crawl less of those pages by using methods like disallowing them in robots.txt.
You can then start influencing it to crawl more of your important pages by optimizing your site’s architecture and internal linking to make them more prominent and discoverable.
More Resources:
- How Search Engines Crawl & Index: Everything You Need to Know
- Crawl-First SEO: A 12-Step Guide to Follow Before Crawling
- Advanced Technical SEO: A Complete Guide
Image Credits
All screenshots taken by author, September 2019
